
meta携手斯坦福大学,推出全新AI模型系列Apollo,显著提升机器对视频的理解能力。
尽管人工智能在处理图像和文本方面取得了巨大进步,但让机器真正理解视频仍然是一个重大挑战。因为视频包含复杂的动态资讯,人工智能更难处理这些资讯,不仅需要更多的计算能力,而且如何设计最佳AI视频解读系统,也存在诸多困难。
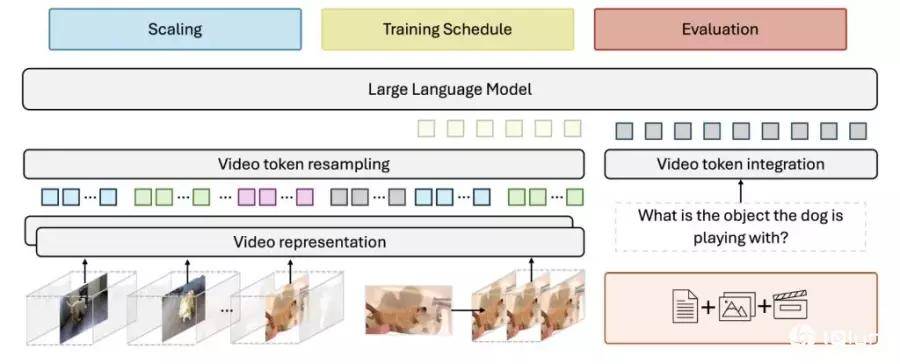
在视频处理方面,研究人员发现,保持每秒恒定的帧采样率能获得最佳结果。因此Apollo模型使用两个不同的组件,一个处理单独的视频帧,而另一个跟踪对象和场景如何随时间变化。目前最常可以处理一小时的长视频。
此外,在处理后的视频片段之间添加时间戳,有助于模型理解视觉资讯与文本描述之间的关系,保持时间感知。
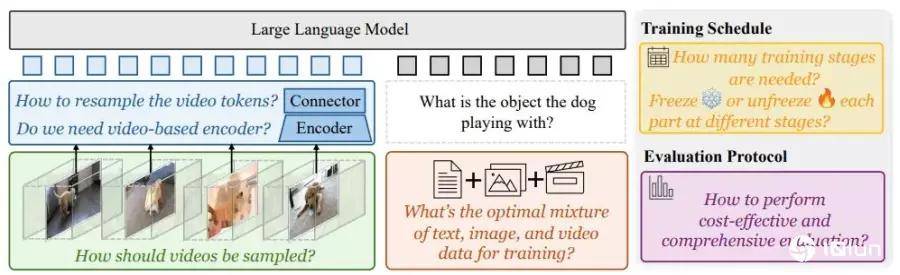
在模型训练方面,团队研究表明训练方法比模型大小更重要。Apollo模型采用分阶段训练,按顺序启动模型的不同部分,比一次性训练所有部分效果更好。
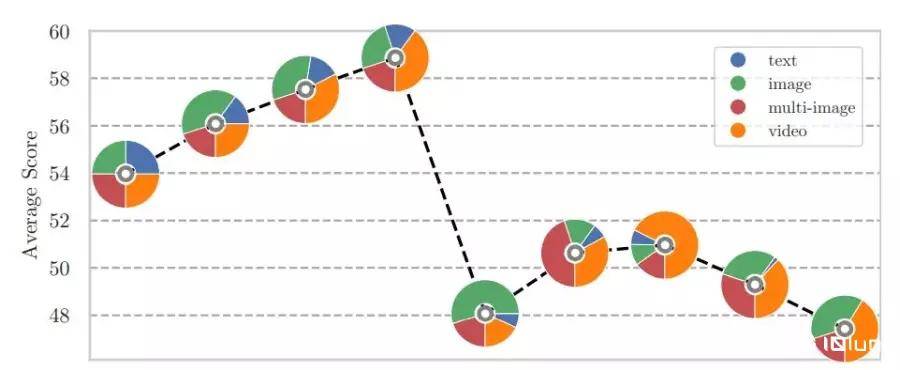
此外meta公司还不断优化数据组合,发现10-14%的文本数据,其余部分略微偏向视频内容,可以更好地平衡语言理解和视频处理能力。
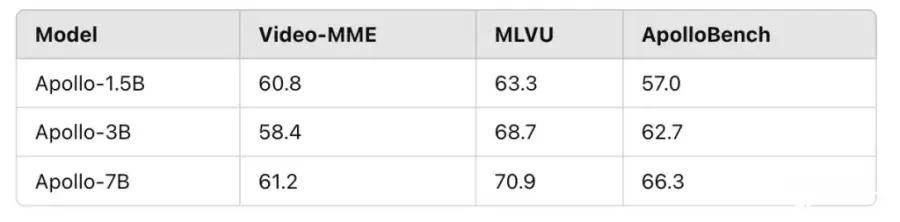
Apollo模型在不同规模上均表现出色,较小的Apollo-3B超越了Qwen2-VL等同等规模的模型,而Apollo-7B超过更大参数的同类模型,meta已开源Apollo的程序代码和模型权重,并在Hugging Face平台提供公开展示。
参考
meta's new Apollo models aim to crack the video understanding problem
meta AI Releases Apollo: A New Family of Video-LMMs Large Multimodal Models for Video Understanding
Apollo: An Exploration of Video Understanding in Large Multimodal Models






 京公网安备 11011402013531号
京公网安备 11011402013531号