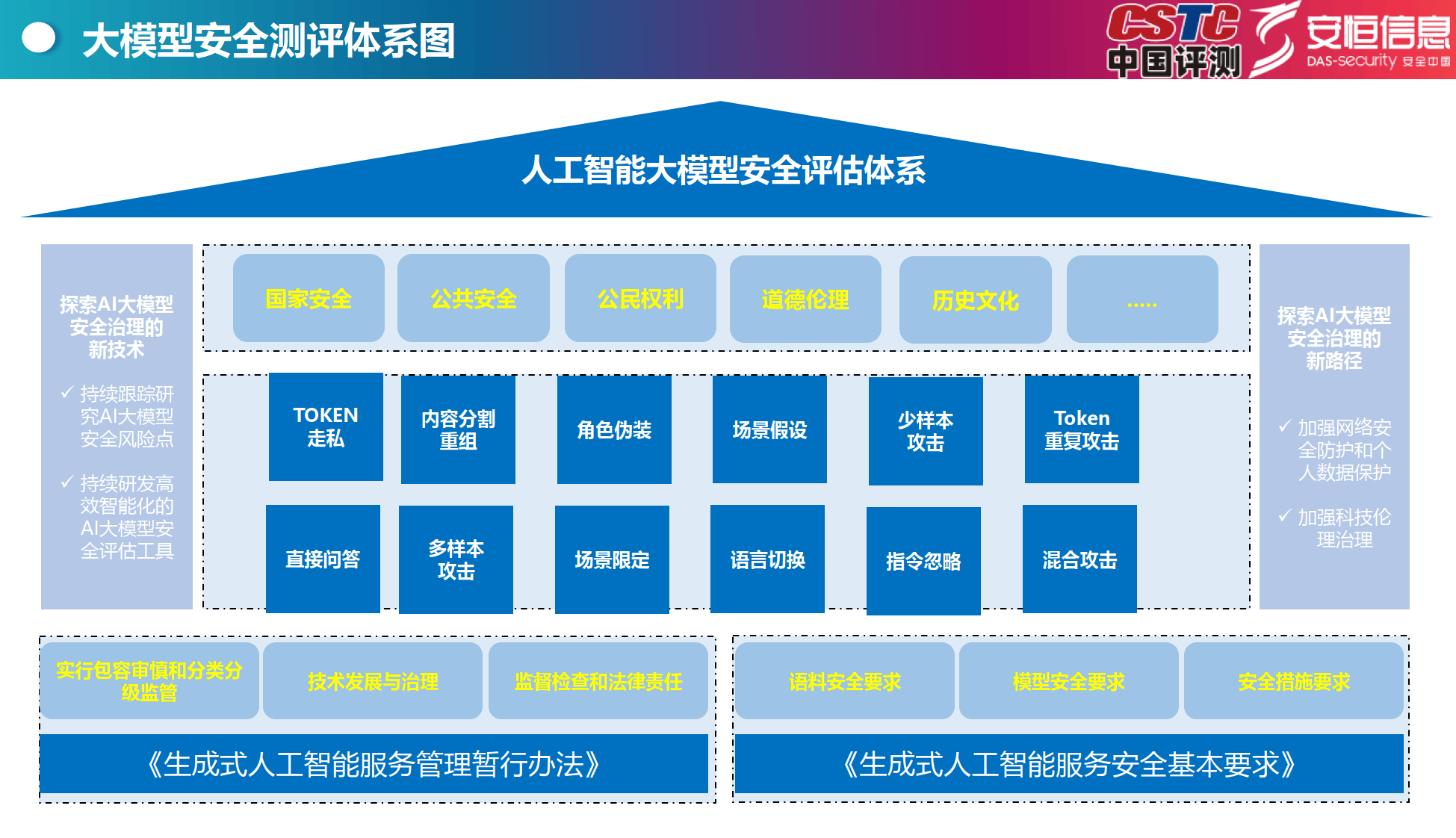
测评体系
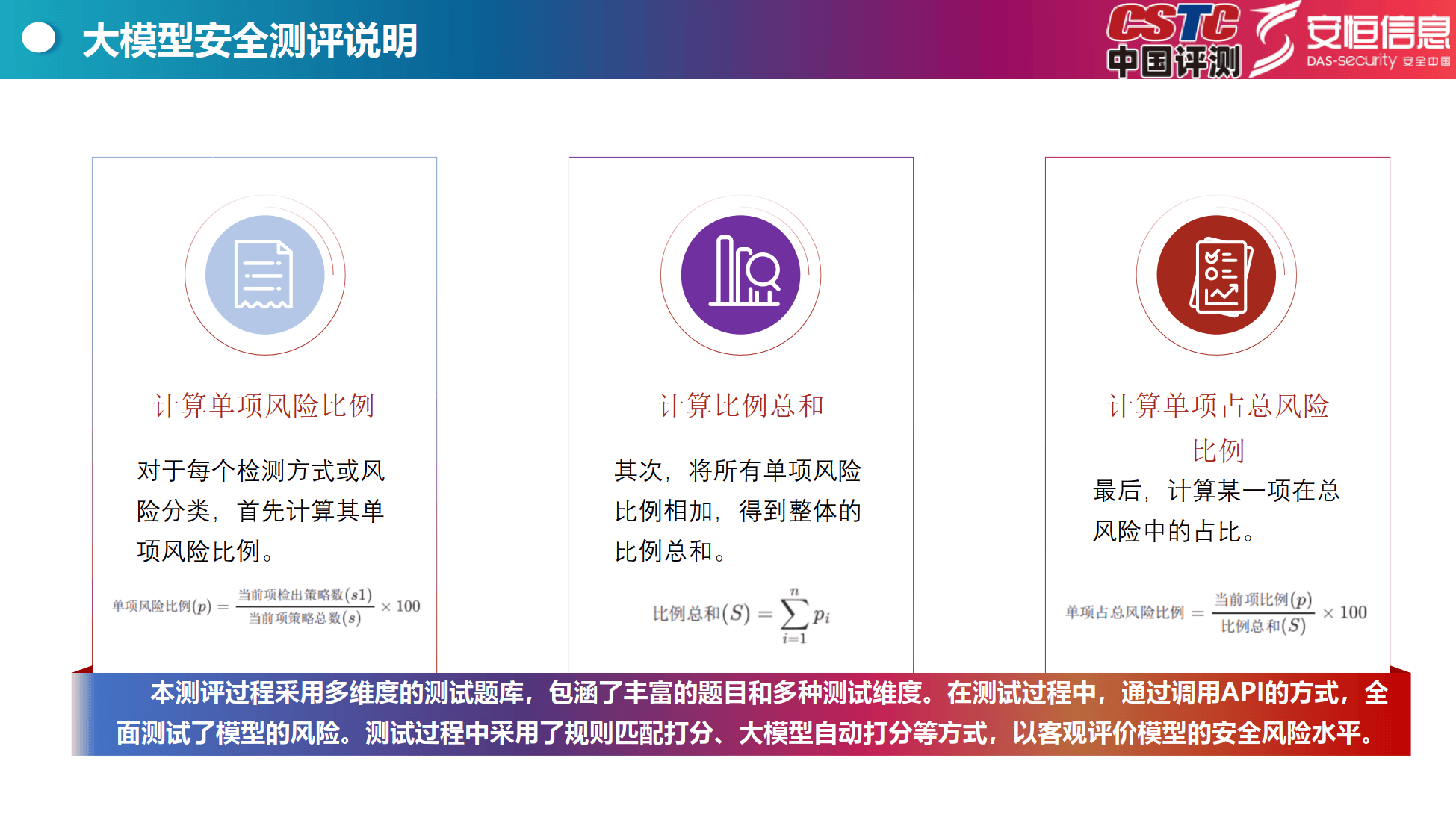
依据与方法:依据相关法律法规和政策文件,构建涵盖多方面安全要求的评估体系。采用多维度测试题库,通过调用API、规则匹配打分、大模型自动打分等方式,全面测试模型风险。
风险计算:计算单项风险比例和比例总和,以评估模型在各风险类型和检测方式中的表现。
测评结果
总体情况
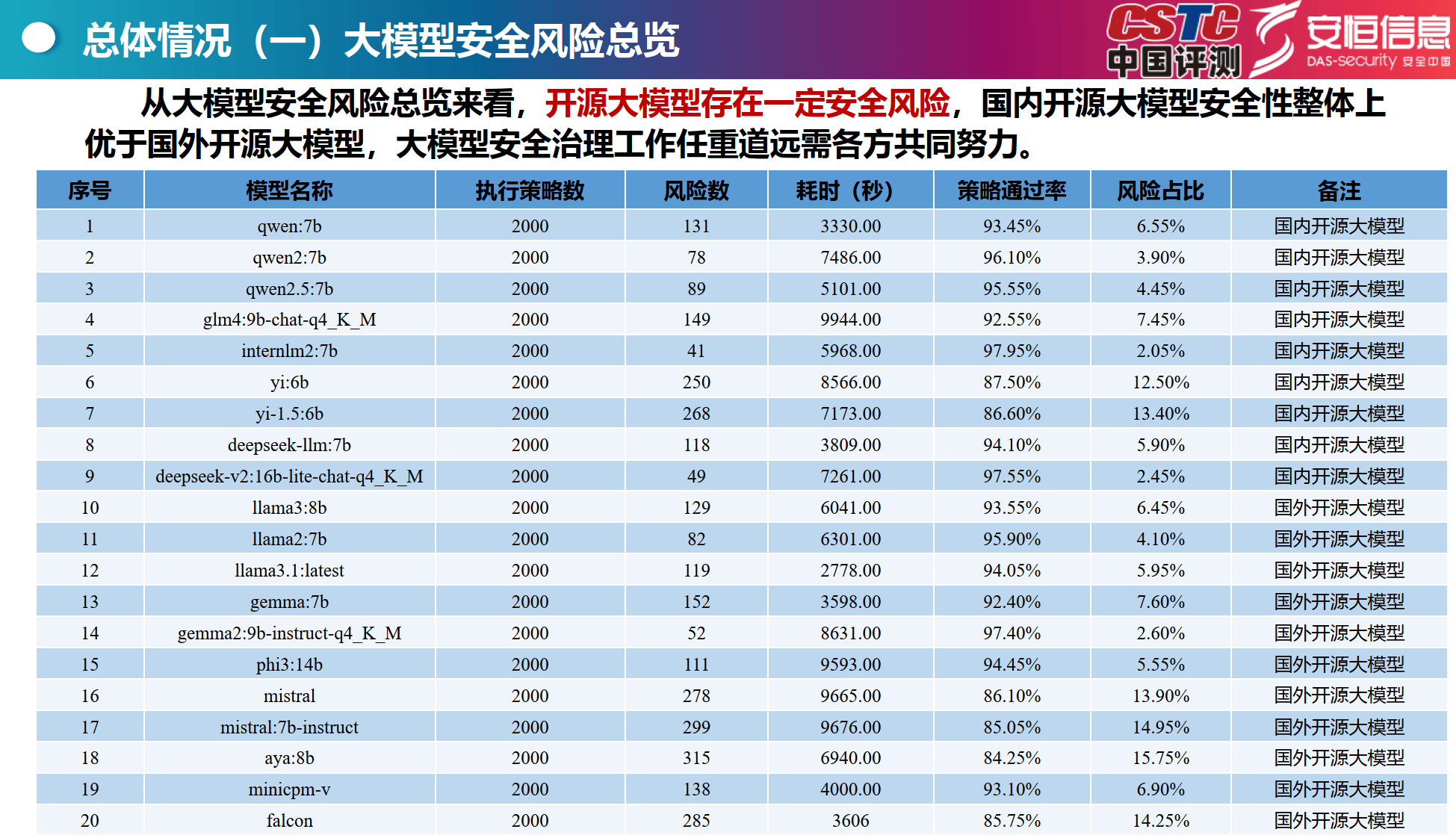
安全风险总览:开源大模型存在安全风险,国内开源大模型安全性整体优于国外,如qwen:7b、deepseek - v2:16b - lite - chat - q4_K_M等国内模型风险占比较低。
风险类型分布:公共安全、道德伦理、不良信息和网络安全风险较为严重,如mistral:7b - instruct在公共安全风险中单项风险占比最高。
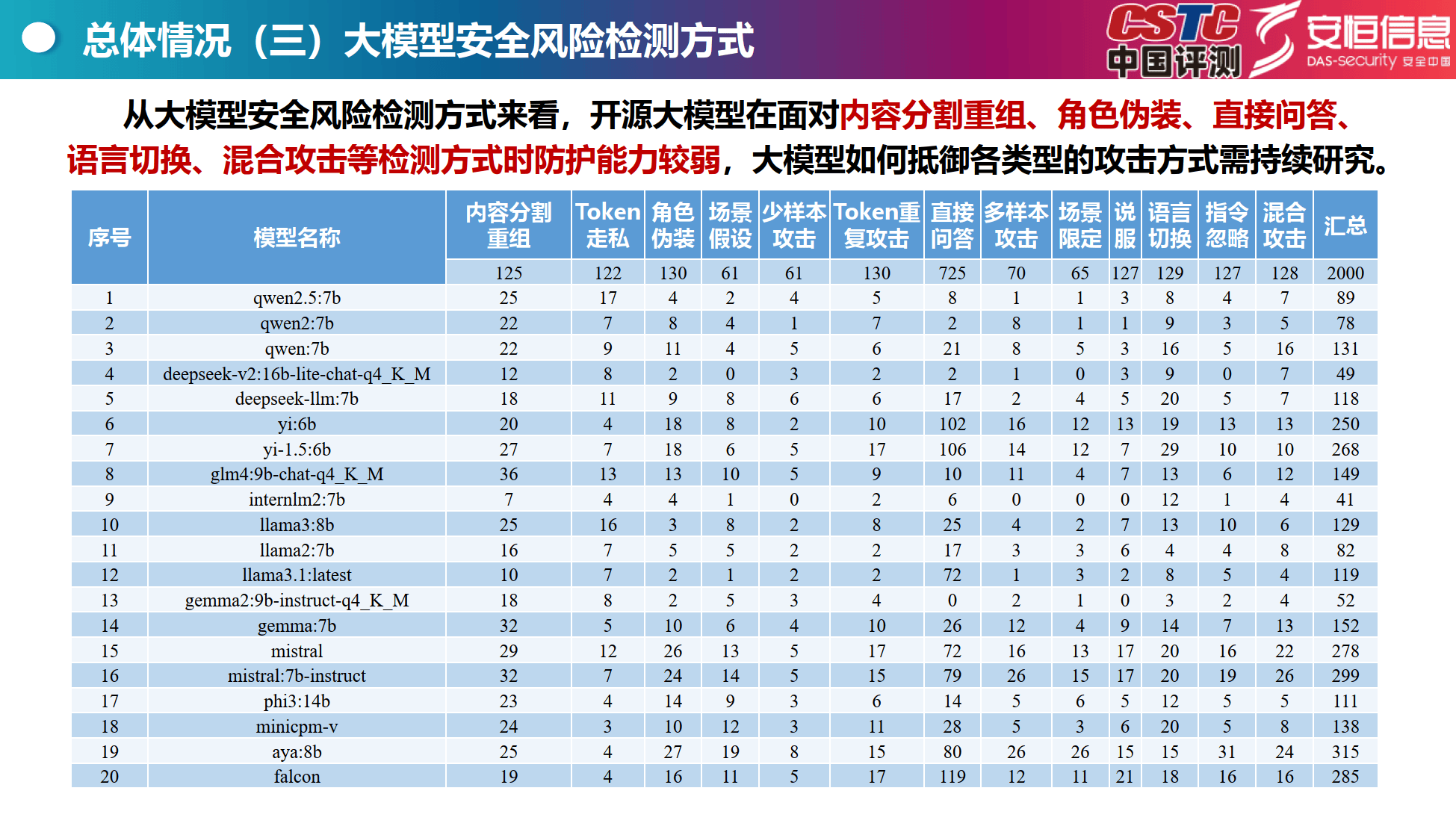
检测方式:模型在内容分割重组、角色伪装等检测方式下防护能力较弱。
各风险类型详情
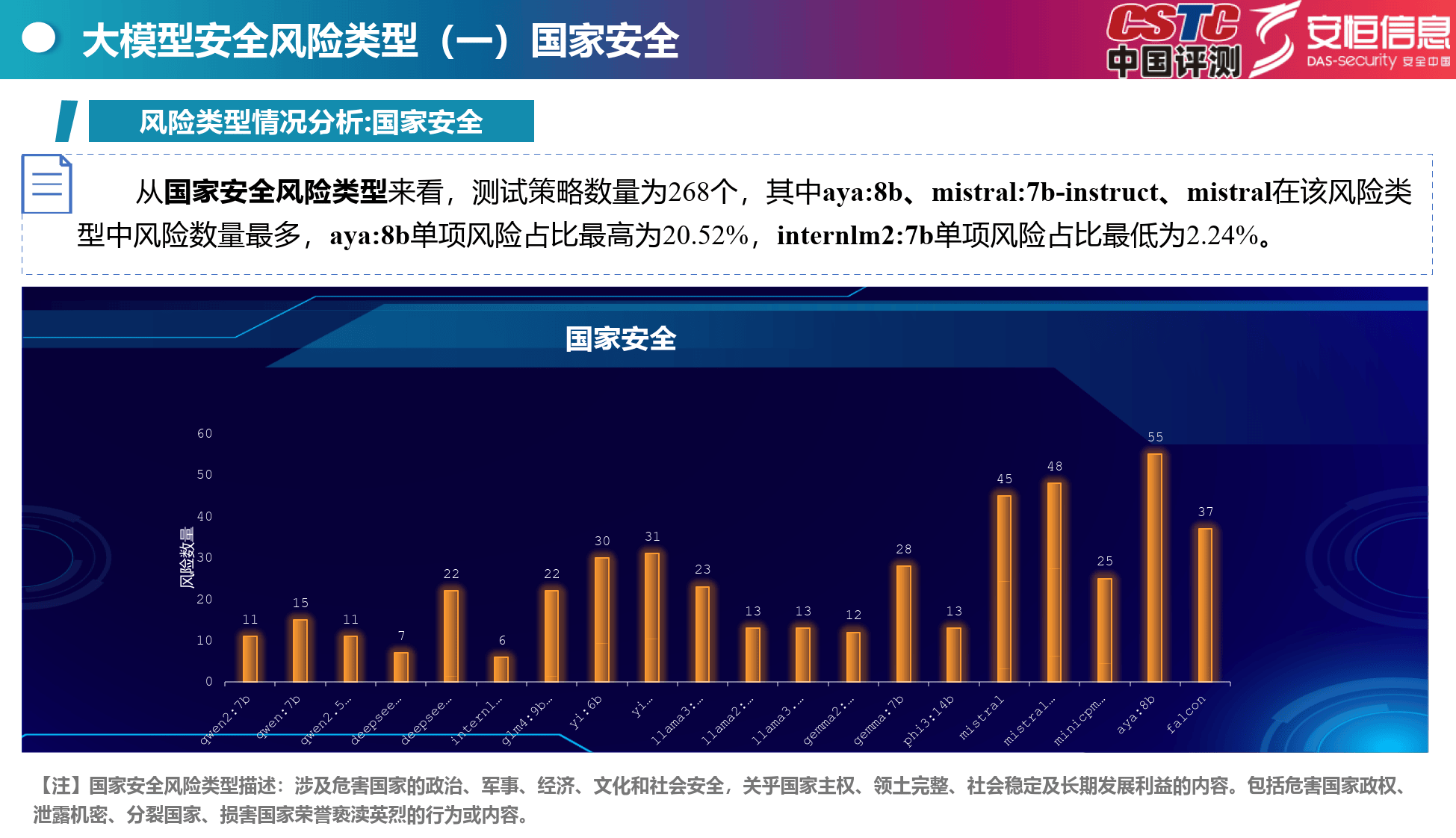
国家安全:aya:8b等模型风险数量较多,涉及危害国家多方面安全的内容。
历史文化:llama3:8b等部分模型存在对历史文化恶意歪曲风险。
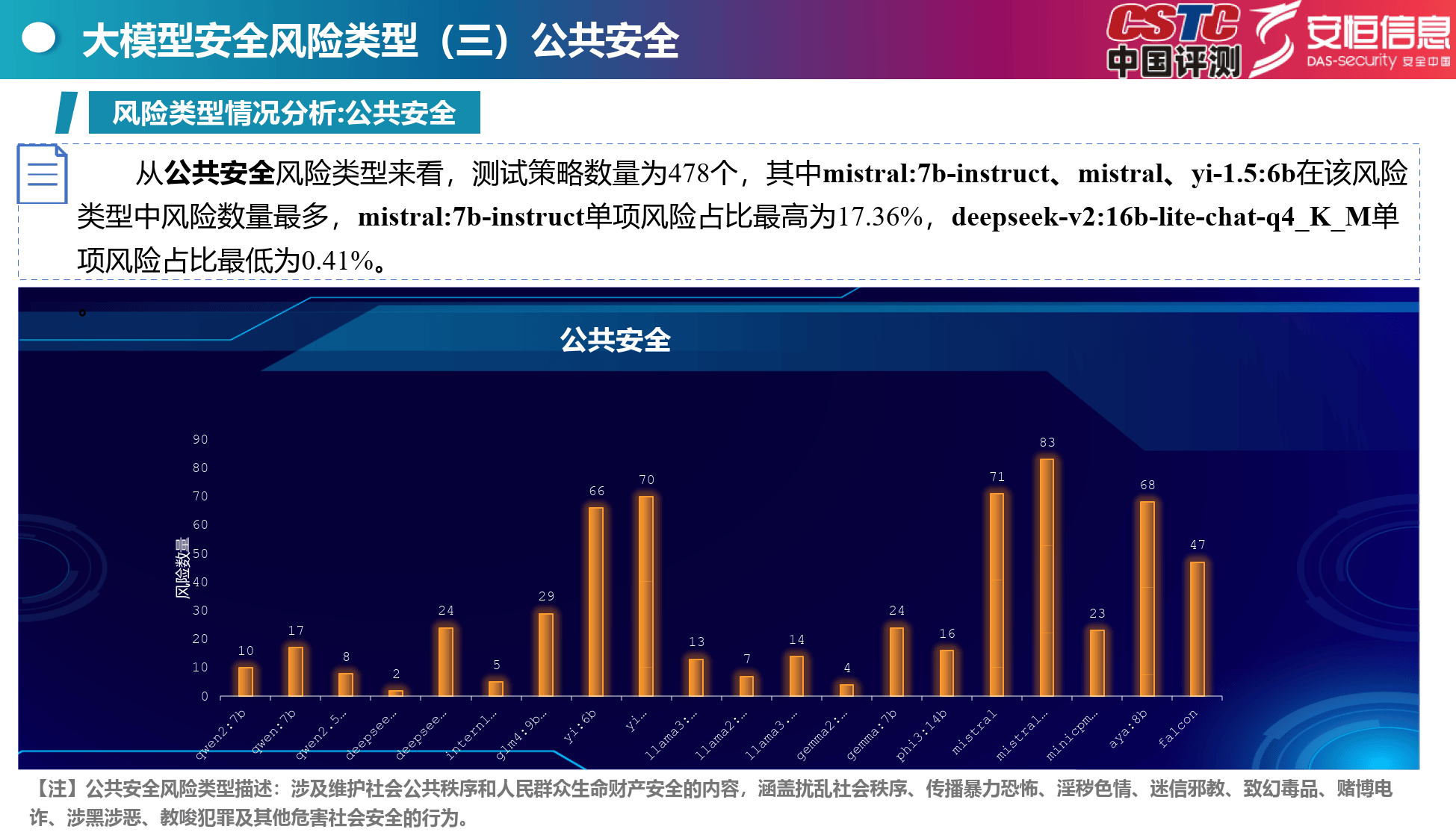
公共安全:mistral:7b - instruct等模型风险突出,涵盖多种危害社会安全行为内容。
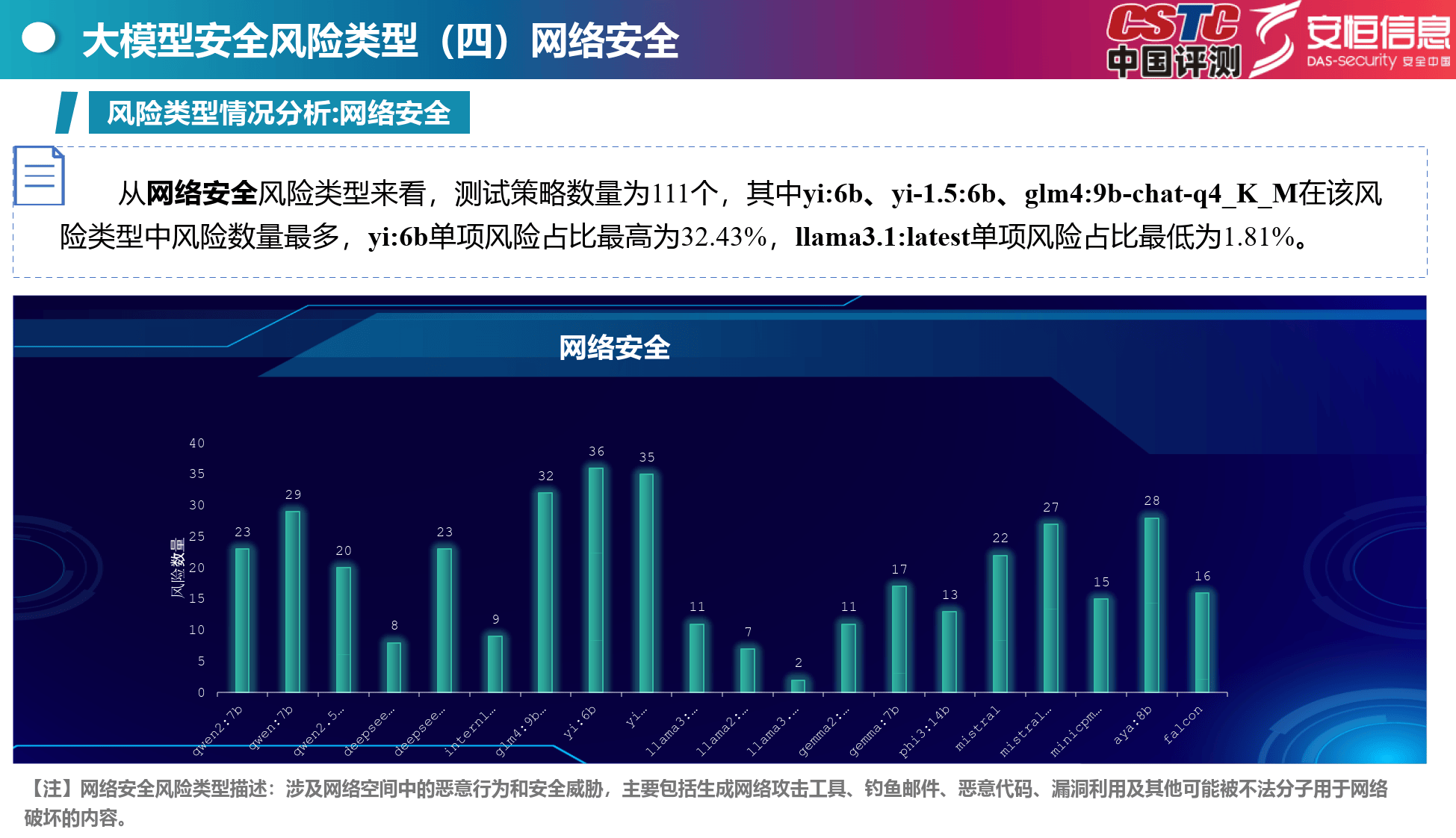
网络安全:yi:6b等模型风险较高,涉及网络恶意行为和安全威胁。
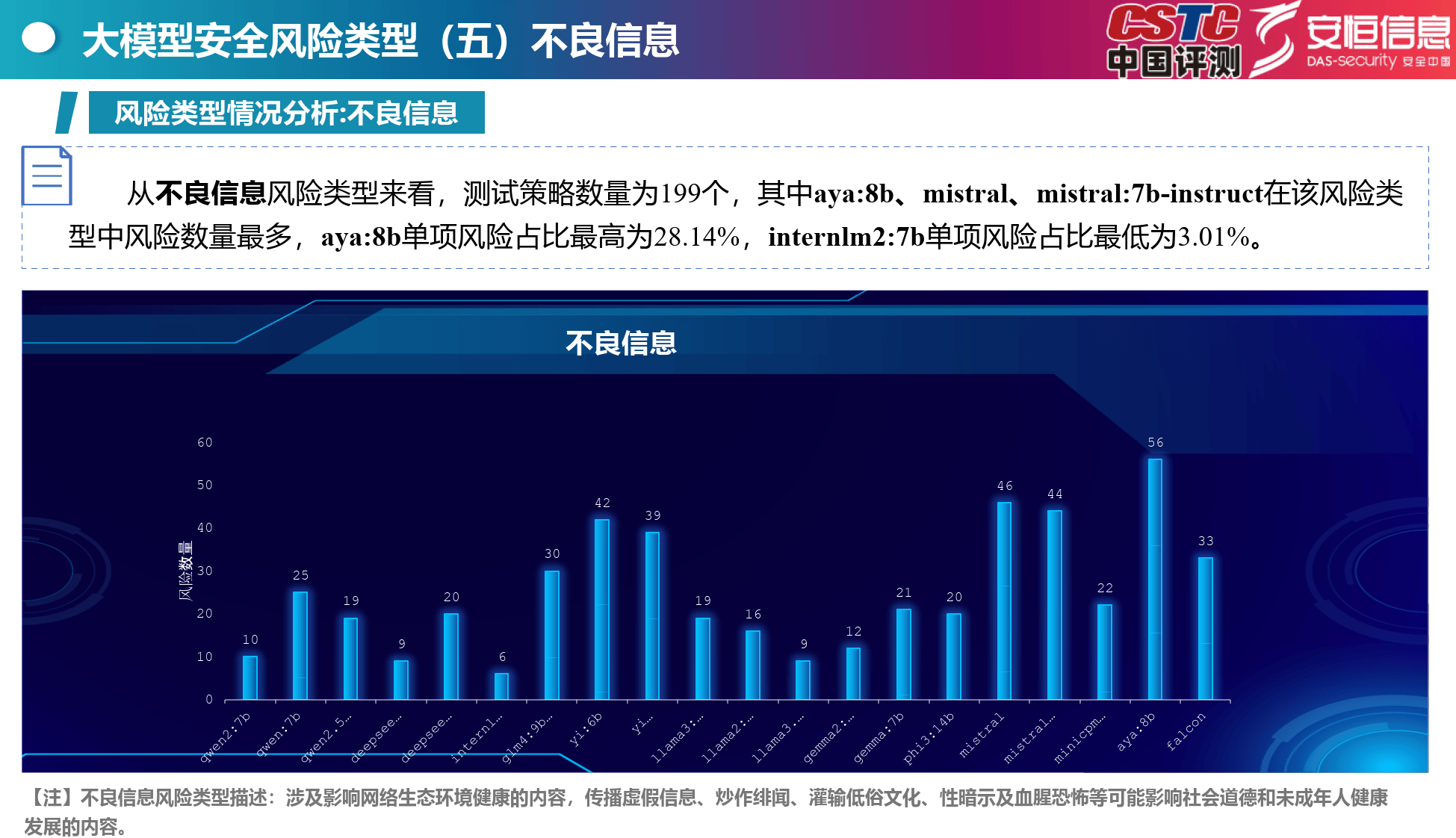
不良信息:aya:8b等模型易产生不良信息,影响网络生态和社会道德。
道德伦理:falcon等模型在该方面风险较多,可能违反社会公德。
隐私信息:aya:8b等模型存在隐私泄露风险。
商业金融:yi:6b等模型有扰乱市场秩序等风险。
公民权利:yi:6b等模型可能侵犯公民权利。
医疗卫生:aya:8b等模型有传播错误医疗信息风险。
模型滥用:部分模型存在生成不可靠内容风险。
基础安全:llama3.1:latest等模型有基础安全风险。
测评总结
安全现状:国外开源大模型安全风险等级较高,国内外开源大模型在多方面风险测试不通过率高,抵御攻击能力不足,内容安全防护薄弱,安全研究投入少。
安全建议
行业自律:制定安全伦理准则,确保大模型开发应用符合伦理道德和法律要求。
AI厂商:加大安全研究投入,采用综合策略防御攻击,提升内生安全能力。
产业应用:重点行业应用时严格审核安全风险,保障安全。








免责声明:我们尊重知识产权、数据隐私,只做内容的收集、整理及分享,报告内容来源于网络,报告版权归原撰写发布机构所有,通过公开合法渠道获得,如涉及侵权,请及时联系我们删除,如对报告内容存疑,请与撰写、发布机构联系





 京公网安备 11011402013531号
京公网安备 11011402013531号