OpenAI圣诞季“十二连发”的第三个工作日,迎来了重头戏——万众期待的OpenAI视频生成模型Sora正式版发布!
OpenAI官方甚至直言 :“Sora就是我给你们的假期礼物。”
今年2月,Sora首次问世便以其卓越的表现震撼了科技届。而此次OpenAI发布更高级的Sora Turbo,在生成视频的速度和效果上,显然更快、更强!
01 Sora的创新表现
整体来说,Sora展示的一系列功能,在视频生成的质量、功能的独创性、技术的复杂度等方面,超出了目前市场上已有的文生视频产品。
OpenAI在直播中介绍,Sora支持从480p到1080p的全系列分辨率,单个视频最长可达20秒。用户可以通过文本描述(文生视频)、图片(图生视频)以及现有视频(视频生视频)来生成视频内容。
特别值得一提的是,Sora上线全新UI界面以及丰富的编辑工具,以便创造者对视频进行修改、创建、扩展、循环、混合。
例如,Storyboard(故事板)允许用户通过时间轴来控制视频内容,添加分镜头,以及调整动作或画面的持续时长。Re-cut(剪辑)是在故事板上对视频进行修剪和延展,实现更精确的视频编辑。Blend(混合)则是将两个视频内容进行过渡和融合,创造出新的视觉效果。
02 Sora的技术原理
OpenAI已经给我们展示了Sora的“全能进化”。这些独特的创新功能极大地拓展了创作者的创作空间,让视频更接近创作者的自我表达、帮助他们完成一个理想的镜头故事。
如此强大的功能背后有哪些黑科技,Sora是怎么做到的?
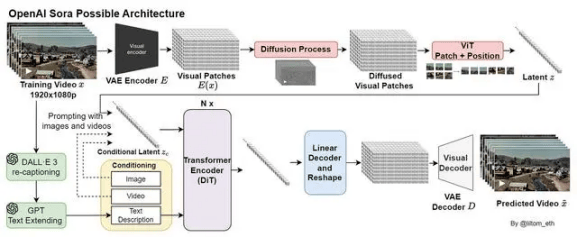
Sora的设计灵感来源于大型语言模型(LLM),通过训练互联网规模数据来获得通用能力。大语言模型使用文本标记,而Sora则使用之前已被证明是用于视觉数据模型的有效表示的视觉“碎片/补丁”(patches)来达到类似效果。
OpenAI首先通过对视频进行时间和空间上的压缩,将其压缩到一个更低维的潜在空间(可将这个潜在空间看做是时空碎片的集合),然后将原视频转化为这些碎片/补丁(patches)。让它们充当像转换器中的标记符号一样的角色,使Sora模型可以在不同分辨率、持续时间和宽高比的视频和图像数据集上进行训练。
然后,Sora利用一种基于Transformer的模型,根据给定的文本提示和已经提取的空间时间补丁,开始生成最终的视频内容。在这个过程中,模型会“涂改”初始的噪声视频,逐步去除无关信息,添加必要细节,最终生成与文本指令相匹配的视频。
此外,训练从文本到视频的生成系统,还需要大量带有对应文本字幕的视频。为此,OpenAI借鉴了DALL-E 3中提出的re-captioning技术,将其应用到视频上。首先训练了一个高度描述性的字幕模型,之后用它为训练数据集中的所有视频生成文本字幕,以此来提高文本逼真度以及视频的整体质量。
03 文生视频模型背后的数据
总的来说,Sora模型凭借其强大的数据处理能力和深度学习能力,成功地将文字与视频内容紧密地联系在一起,为用户带来了前所未有的视频生成体验。这个模型就像是AI的“大脑”,里面存储了海量的视频和图像信息。通过不断学习这些数据,模型得以建立对现实世界中各类场景、情境、运动规律以及人类活动特征的深度理解和精准捕捉。
其中,高质量视频训练数据在提升输入文字与生成内容匹配度方面扮演着至关重要的角色。不仅能够提升模型的性能,还能够为用户提供更加真实、准确和连贯的视频生成体验。
标贝科技始终专注于为企业提供高质量的精标数据服务以及丰富的多模态数据资源。针对大模型数据需求,我们精心打磨了多模态大模型数据解决方案,覆盖从数据采集、预处理、清洗、标注到质检等系列工程化流程,积累了高质量的多模态大模型训练数据集,为客户打造优质的服务体验。
04 标贝科技多模态大模型训练数据-视频caption数据集
视频caption数据样例1:生活类
视频caption数据样例2:运动类

视频caption数据样例3:动物类

视频caption数据样例4:其他







 京公网安备 11011402013531号
京公网安备 11011402013531号