
一只戴着红色围巾的企鹅闯进了火热的AI视频战场。
刚刚,腾讯混元发布了AI视频生成大模型。

腾讯混元文生视频官网:https://aivideo.hunyuan.tencent.com
AI文生视频功能已经在腾讯元宝上线,大家可以点击“腾讯元宝App-AI应用-AI视频”来申请试用。企业客户可通过腾讯云提供服务接入,API同步开放内测申请。
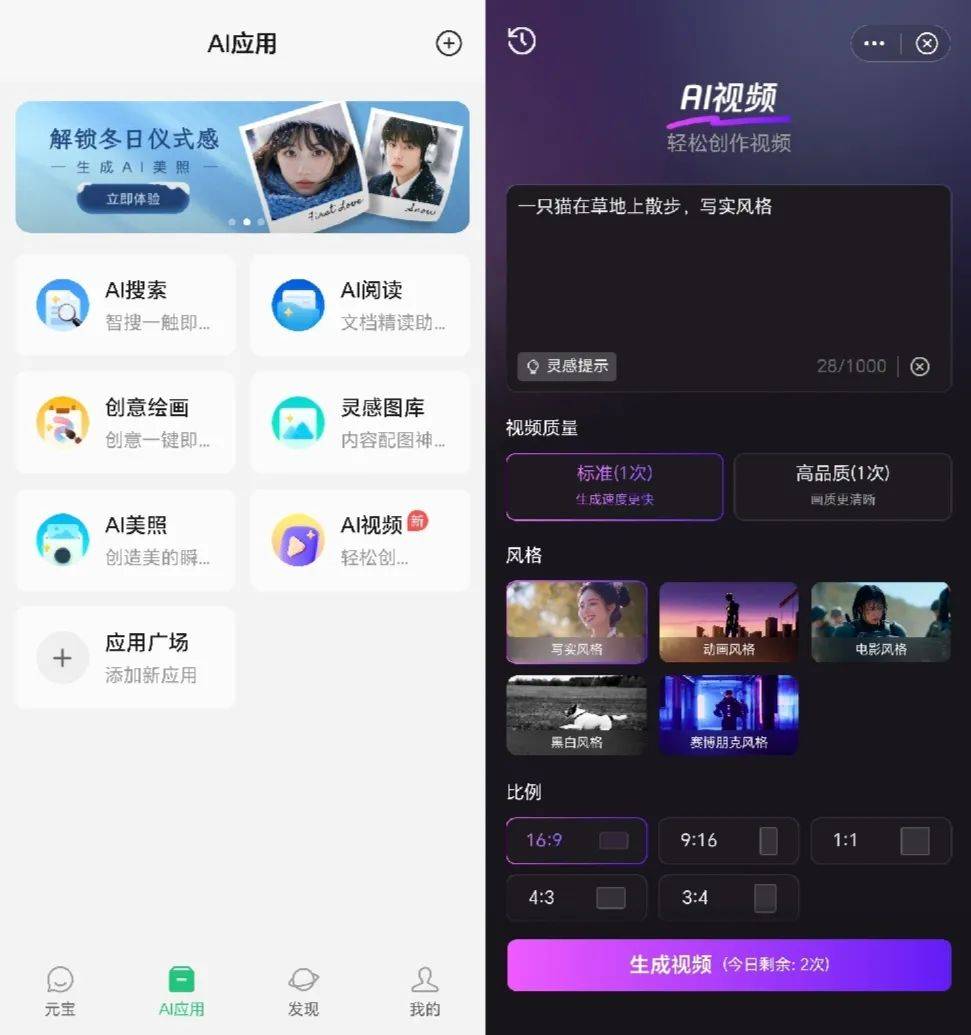
腾讯元宝AI视频页面
据官方数据,与国内外多个顶尖模型的评测对比显示,混元视频生成模型在文本视频一致性、运动质量和画面质量多个维度效果领先,在人物、人造场所等场景下表现尤为出色。
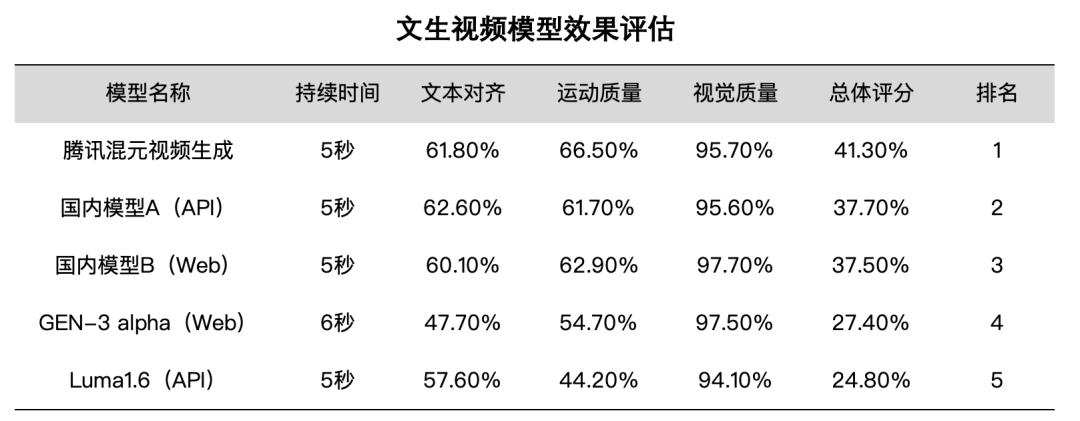
更夸张的是,混元视频生成模型的参数量达130亿,腾讯直接对外开源了,包含模型权重、推理代码、模型算法等完整模型,企业和个人开发者可以在Hugging Face、Github上免费使用和开发生态插件。
这可是目前最大的视频开源模型。市面上免费的AI视频产品很少,腾讯这把还是太豪了
。
近几个月来,海内外闭源的AI视频模型已经卷到飞起,腾讯这时候开源的模型效果究竟如何?
“AI”参与了最近混元视频的小范围内测,已经上线的文生视频默认生成时长为5秒,支持中英文双语输入,可以选择多种视频尺寸和清晰度,该有的基本功能都有了。
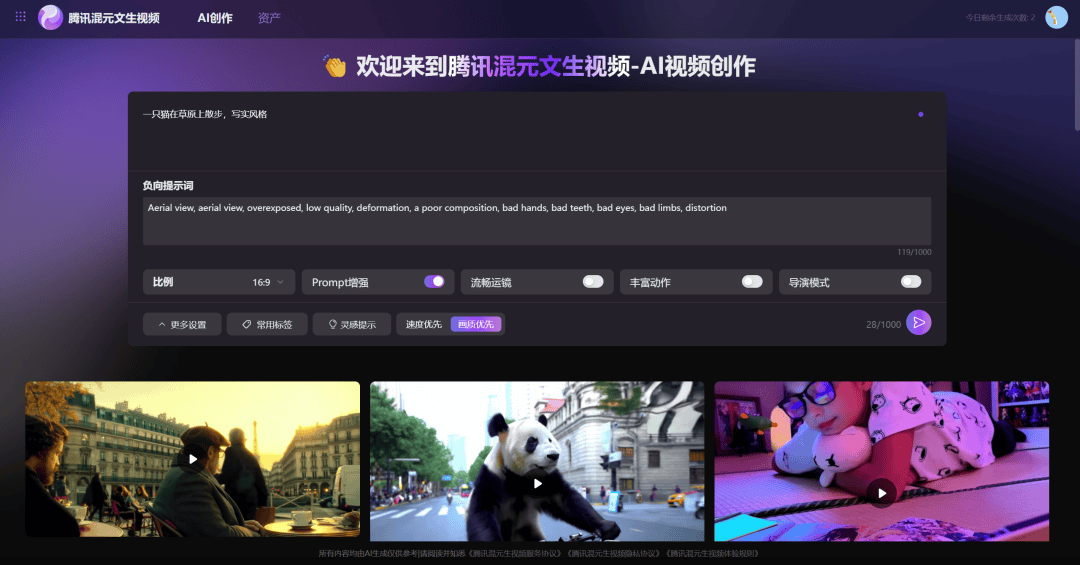
腾讯混元文生视频网页端:https://video.hunyuan.tencent.com/
根据我们的测试案例来看,混元视频模型擅长写实的视觉风格,对于提示词的理解遵循比较出色,运动幅度也比较大,画面质量在一众AI视频产品中位于前列。
尤其令人惊喜的是,混元视频原生支持多镜头切换,可以在5秒内保持同一主体自动切镜。
基于混元视频,我们生成了这条AI猫猫泡温泉的短视频,有没有萌到你呢?
以下是我们更详细的关于混元文生视频的实测案例,欢迎在评论区和我们分享你的看法。
ps.关注“AI”公众号,后台回复关键词“混元视频”,可获取我们的完整测试文档。
混元文生视频五大能力实测
我们从视觉风格、语义理解、运动表现、运镜和文字生成5个方面,对混元文生视频进行了实测。
1. 视觉风格
先来看看混元在面对多元化风格提示词的适应性和表现力,官方预设的风格包括写实、动画、电影、黑白和赛博朋克。
一位正在弹钢琴的小女孩,背后挂满星星灯,温暖的家庭客厅,摆满了圣诞装饰,镜头从小女孩的背后平移环绕到侧面,特写与中景交替,柔和暖光,童话般梦幻。

乍一看,这个例子很像现实拍摄的场景,除了“星星灯”的位置不对以外,整体的光影和氛围感很真实、温馨,小女孩的手指也未出现畸变,运镜很平稳。
圣诞老人坐着雪橇滑行在下着雪的街道,街道两旁是乐高积木搭建的房屋,屋顶上覆盖着厚厚的积雪,全景镜头,镜头略微推近,乐高动画风格,具有乐高积木的独特质感。场景中充满了童趣和幻想,展现出一个充满欢乐和奇迹的圣诞节。

乐高动画风格的圣诞创意街景非常生动,甚至雪橇的运动还模拟出了乐高积木坚硬的感觉。
卓别林正在流水线上忙碌地工作,双手拿着扳手不停地拧螺丝,使用黑白电影风格拍摄,默片,老电影,中景, Static High-quality Black and white

黑白风格的画面还有胶片特有的颗粒感,卓别林的形象也比较准确,不过现实中其他名人或IP形象为避免侵权是无法生成的,比如马斯克、Hellokitty。
总的来说,混元基本能在呈现特定艺术风格和元素的同时,保持画面的整体美感与和谐性,但整体效果仍偏写实。
2. 语义理解
文生视频最关键的部分就是提示词,不仅关系到生成视频的视觉一致性,也决定着最终生成内容能否满足创作者的预期表达。
一般来说,建议大家输入具体的、结构化的提示词,包括主体特征、场景描述、情感氛围、光线运用和运镜控制等,可以参考以下格式:
用法1: 提示词 = 主体+场景+运动
用法2: 提示词=主体(主体描述)+场景(场景描述)+运动(运动描述)+(镜头语言)+(氛围描述)+(风格表达)
用法3: 提示词 = 主体+场景+运动 + (风格表达) + (氛围描述) + (运镜方式) + (光线) + (景别)
懒得想提示词的话,我们创建了一个优化AI视频提示词的智能体,有需要的玩家可以移步腾讯元宝使用。

https://yuanbao.tencent.com/bot/app/agent/HJbwskepImvE
据腾讯介绍,混元视频模型在技术上引入多模态大模型作为文本编码器,可以更好地理解复杂文本,emoji都能理解,一两百字的提示词不在话下,但是目前5秒时长不建议写这么长。
混元本身也提供了两种优化提示词的模式:prompt增强和导演模式。
prompt增强旨在增强视频生成模型对用户意图的理解,从而更准确地解释所提供的说明。
导演模式会增强对构图、光照和摄像机移动等方面的描述,倾向于生成具有更高视觉质量的视频,但这种强化有时也可能会导致丢失一些语义细节。所以大家还要具体需求来选择使用。
像这个小女孩抱着发光熊的例子就开启了导演模式,自动增加了前后移动的运镜效果,泰迪熊的光效柔和自然,小女孩的动作逻辑也很合理。
一个小女孩在温馨的卧室,穿着睡衣抱着一个发光的泰迪熊,梦幻童话风。

而下面这两个提示词本身比较详细,没有开启导演模式。
一棵完全由巧克力制成的圣诞树,巧克力呈现出不同深浅的棕色和奶油色,顶上有巧克力小星星,表面光滑,质感细腻。创意广告风格,3D效果逼真,色彩鲜明,对比强烈,突出巧克力的质感和细节。背景色为纯白色,可以有轻微的阴影效果,镜头缓慢旋转,环绕巧克力圣诞树进行360度展示。

日漫风格,动画,一个10岁左右的中国小女孩,黑色短发,面容可爱,穿着红色连衣裙和白色运动鞋。她坐在时光机上,脸上露出兴奋和好奇的表情。时光机启动后开始加速,穿越时空隧道。隧道内的光线和色彩不断变化,形成流动的光影效果。镜头从时光机的侧面缓慢跟随,捕捉时光机启动和加速的全过程。场景充满未来感和奇幻氛围,传递出一种冒险和探索的感觉。

可以看到,混元对于复杂的提示词理解还是比较到位的,关键信息都表现出来了,部分细节略有缺失或不一致。
3. 运动控制
AI能否根据提示词准确再现主体和场景的动作特征,是否具备真实、自然、流畅的物理表现力,是目前AI生成视频模型的一大难题。同时,运动表现也是衡量画面连贯性的重要标准,细腻流畅的动态细节通常能大大提升画面的真实感。
动态元素常涉及主体的动作、场景的变化以及整体节奏的把控,这些都要求AI生成模型具备高度的物理理解能力和画面细节的动态呈现能力。
戴墨镜的老绅士,拄着拐杖缓慢走在欧洲小镇街道,两旁是咖啡馆和书店,氛围怀旧忧郁,固定镜头,自然光,晨光洒在地面。

一个老人走路的简单动作,混元对于视频主体“戴墨镜的绅士”、场景背景的欧洲小镇街道、两旁的咖啡馆与书店基本都准确呈现,与提示词中的描述一致,老人走路的步伐和拄拐动作也基本协调流畅,氛围方面确实有一种怀旧和忧郁感。
一只可爱的泰迪熊毛绒玩偶在桌面上像人一样跳舞,左右手挥动,双脚交替跳跃,然后转身向上蹦,写实风格,泰迪熊没有穿衣服,脖子上有个小小的黑色领结。

混元文生视频可以根据“[主体描述]+[动作描述] + [然后、过了一会等连接词] + [动作描述2]”的提示词格式,生成两个连贯动作。
可以看到这个视频中的小熊动作非常流畅连贯,除了转身之外,提示词提到的所有动作都完成了,并且在运动过程中保持了主体和背景的一致。
4. 运镜
自然流畅的镜头语言如推拉、平移、升降等,以及丝滑的切镜,是展现视频场景的空间感和叙事层次感的关键。
混元本身也有一个“丝滑运镜”的模式,据我们的实测,打开这个模式可以让运镜更流畅平滑,消除镜头移动中的生硬或不自然过渡。
我们在提示词里也加入了对镜头角度、移动方式、景别切换的描述,来看看生成效果。
一名穿连帽衫的涂鸦艺术家,手持喷漆罐创作壁画,城市暗巷,墙面布满色彩鲜艳的涂鸦,艺术家快速挥舞手臂喷涂,颜色渐渐覆盖墙面,街头文化风,色彩浓烈,热血且充满创造力,快速切镜,捕捉喷涂动作与画面细节交替,特写展示喷漆与颜料,中景展现完整画作。

不愧是原生支持切镜,混元准确呈现了喷涂的动作和镜头切换,喷漆和涂鸦的细节也较为细腻。
一辆复古敞篷车快速行驶在沿海公路上,一侧是湛蓝大海,一侧是悬崖峭壁,驾驶者头戴圆形墨镜和丝巾,背景风景逐渐被抛在身后,从近景切换到远景,展现海岸线的壮丽,清晨的阳光,带有些许柔和的金色光晕。

这个例子更是令人惊艳,从驾驶者的第一视角很自然地切换到驾驶者的特写,女人面部的光影明暗变化质感很强,不过墨镜上的映像是固定不变的,不太符合实际。
通常,图生视频可以更好地保持主体一致性,但需要先批量生图再生成视频,现在混元在文生视频上升级了转场切镜能力,简化了操作流程,可以进一步提高视频创作效率。
5. 文字生成
相比AI图像模型,目前AI视频模型生成文字的表现普遍不够精准,可以生成较短的英文字母和数字,而生成的中文还无法辨认。
比如混元可以生成英文“AIGC”,彩色灯效也能同时呈现,不过可控性一般,需要多次尝试。
镜头缓缓推近,一面昏暗的墙上有一个灯箱闪烁了几次,然后亮起文字“AIGC”,发出彩色的灯光,赛博朋克风格。

数字也可以生成,我们尝试用草莓来组成数字“6”,虽然草莓掉落的运动还有点问题,但数字形状是准确的。
高速镜头拍摄,把许多草莓向上抛向空中,然后镜头变成俯视拍摄,草莓落到桌面上组成了数字“6”,黑色背景,美食摄影,明亮。

总的来说,腾讯混元AI视频表现出了还不错的综合能力,中英文提示词生成的效果差不多,但也存在一些老生常谈的局限,例如细节处理失真,可控性有待提升,水墨等视觉风格还不够多样化,物理运动和镜头切换可能有不符合常理的地方。
以上是我们测试的部分案例,关注“AI”公众号,后台回复关键词“混元视频”,可获取我们的完整测试文档。
腾讯想要做大AI视频生态
毫无疑问,腾讯混元的入局,让AI视频生成领域的竞争进一步升级。
从技术上看,混元视频基于跟Sora类似的DiT架构,并在架构设计上进行多处升级。混元视频还对多个专项能力进行了微调,包括画质、高动态、艺术镜头、手写、转场、连续动作等,未来将持续迭代增强可控性。
以后我们再提到海内外AI视频产品的封神榜,混元一定是其中的头号玩家。
更重要的是,腾讯选择了走开源这条路,准备将AI视频的生态越做越大。
要知道,相较于图像生成社区,目前,视频生成社区的生态尚未形成气候。一方面,图像生成领域有一批非常成熟的底层模型,并在开源环境下催生了活跃、繁荣的开发者社区。独立开发者可以基于底模和各种Lora,实现1+1>2的效果。
而主流的视频生成模型多为闭源,据腾讯介绍,视频开源模型与闭源模型差距巨大,不仅是算力、数据的巨大差距,而且领先的机构都在闭门造车,与社区脱节。
从年初以来,腾讯混元系列模型的开源速度不断加快。此前,腾讯混元已经开源了旗下文生文、文生图和3D生成大模型。
如今混元视频也全面开源,基于腾讯混元系列的开源模型,开发者及企业无需从头训练,即可直接用于推理,并能基于腾讯混元系列打造专属应用及服务,能够节约大量人力及算力,加速行业创新步伐。
在应用场景方面,腾讯混元视频生成模型已经开始在工业级商业场景发挥作用了,例如广告宣传、动画制作、创意视频生成等场景。人民日报、央视网、新华社等多家媒体已率先使用混元视频制作创意视频,包括江山如此多娇、山水之间等多部作品。
据腾讯透露,未来混元视频还将上线图生视频模型、视频配音模型、驱动2D照片数字人等新能力,让未来AI内容创作更加高效。








 京公网安备 11011402013531号
京公网安备 11011402013531号