现有的大模型几乎都是在Tranformer的基础上开发的,可以说Tranformer就是大模型的基石。这篇文章,作者给我们大家介绍了Tranformer的相关知识,一起来看看。

查阅大模型相关资料时,经常看到NLP、LLM、GPT、ChatGPT、Transformer……这些都是什么呢,之间又存在什么关系呢?
一、关系初识
NLP自然语言处理,是人工智能领域的一个分支,是一种学科/应用领域。而LLM大型语言模型,是NLP领域中的一种特定类型的语言模型,是指一个广泛的分类,涵盖了所有使用大量数据进行训练的、能够处理和生成自然语言的AI模型。而GPT是这一类模型中的一个特定例子,是LLM的一种实现,通过海量数据训练的深度学习模型,能够识别人的语言、执行语言类任务,并拥有大量参数。它使用Transformer架构,并通过大规模的预训练,学习语言的模式和结构;ChatGPT则是基于这些内容而实现出来供我们使用的产品。
1.基于以上的了解,可将LLM、GPT、Transformer、ChatGPT的关系用下图表示:
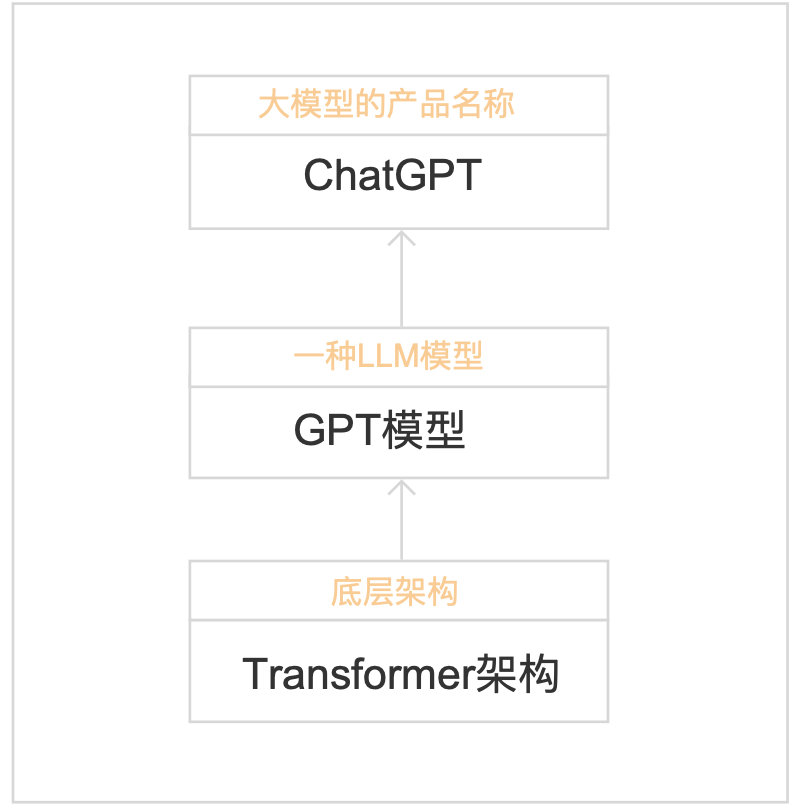
可见Transformer是基础架构,LLM是建立在这种架构上的一类复杂系统,GPT是LLM中的一种特定实现,并通过大量的预训练,获得了强大的语言处理能力。而已发布的ChatGPT使用了GPT技术进行了产品的呈现。
2.为了更好理解LLM、GPT、Transformer三者的关系,我们可将他比作建筑的不同部分:
1)Transformer:基础结构
将其想象为一座大楼的框架,Transformer提供了基本的支撑和形状,里面详细设计为空,决定了建筑的整体设计和功能;
2)LLM:整体建筑
可理解为是建立在前面框架上的整体建筑,不仅有框架(即Transformer架构),还包含了房间、电梯、装饰等,使建筑完整,功能丰富;
3)GPT:特定类型的建筑
可被视为大型建筑中的一种特定类型,如一座特别的摩天大楼,他不仅使用了Transformer架构,还通过特定的方式进行了设计和优化(即大规模预训练),以实现特定的功能,如高效的文本生成和语言理解。
二、Transformer
语言大模型的核心是Transformer,是基于注意力机制的深度学习模型(神经网络架构),用于处理序列到序列的任务。简单来说,就是捕捉句子中不同位置的词之间的关系,用于如理解上下文信息、生成连贯逻辑一致的文本等,且能高效并行计算。
1. Transformer主要核心结构
如下:
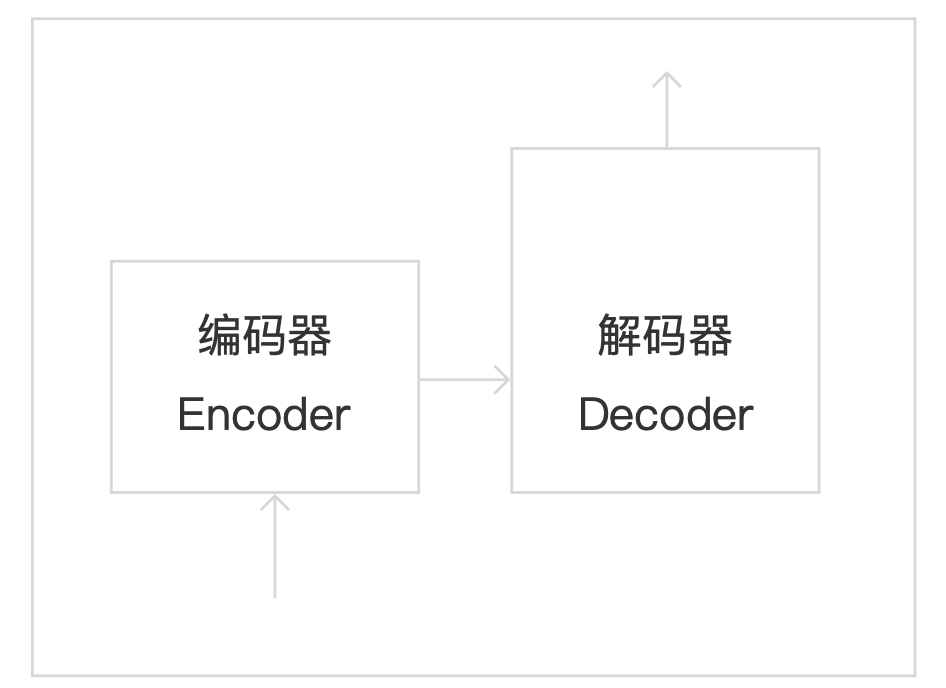
Transformer内部有多个编码器、解码器堆叠;
编码器:主要捕捉输入序列中的信息并建模特征;
解码器:主要生成输出序列;
编码器/解码器堆叠的作用:增加模型性能,有助于处理复杂的输入输出关系。
下面我们深入了解一下Transformer架构:
1)其核心组成部分包含:
i.编码器:
由多个编码器层堆叠而成,内部包含多头自注意力机制+前馈神经网络,整体主要作用是捕捉输入序列的上下文信息,并生成一系列编码向量;
ii.解码器:
由多个解码器层堆叠而成, 内部包含带掩码的多头自注意力机制+编码器到解码器的多头注意力机制(常称为编码器-解码器注意力)+前馈神经网络,整体主要作用是利用编码器的输出生成输出序列。
iii.嵌入层:
将输入序列中的词转换为用向量表示(即词向量),以便模型能够处理;
词向量:
将单词转换为向量,或者说将语言的基本单位转换为数字组合(如将英文单词转换为一串数字,让计算机可识别),核心思想是具有相似语意的词在向量空间中更接近;
向量:表示具有大小和方向的量,如在直角坐标系中(x,y)、在三维空间表示为(x,y,z);
iv.位置编码:
把表示各个词本文顺序的向量和上一步得到的词向量相加;
由于Transformer并行处理输入序列中的所有单词,所以不知道输入序列的顺序信息,因此需要生成每个单词在序列中的位置信息;
2)主要涉及的工作原理:
i.自注意力机制:
允许模型在处理每个单词时关注输入序列中的其他单词,这种机制能给每个词分配一个权重,计算当前词与其他所有词之间的相关性;
作用:理解上下文和语言流的关键(捕捉序列数据中的依赖关系);
ii.多头自注意力机制:
将输入序列分成多个头,并对每个头进行自注意力计算,然后将多个头的结果拼接在一起,最终通过线性变化得到输出。简单的说,每个注意头专注于句子中的某个特定关系(如某一个单头自注意力只关注主谓关系、另一个单头自注意力只关注形容词与名词的关系等),使模型能够从不同角度或多个层面捕捉语意信息;
作用:生成更准确的表示,提高了对复杂关系的建模能力;
iii.前馈神经网络:
在每个编码器与解码器层中,还包括一个位置独立的前馈神经网络,由两个线性层和一个激活函数(通常为ReLu)组成;
作用:对自注意力层的输出进行进一步的非线性变换,强化位置的表示/提取更复杂的特征,增强模型的表达能力;
2. Transformer的内部结构
基于以上的了解,我们来补全一下Transformer的内部结构如下:
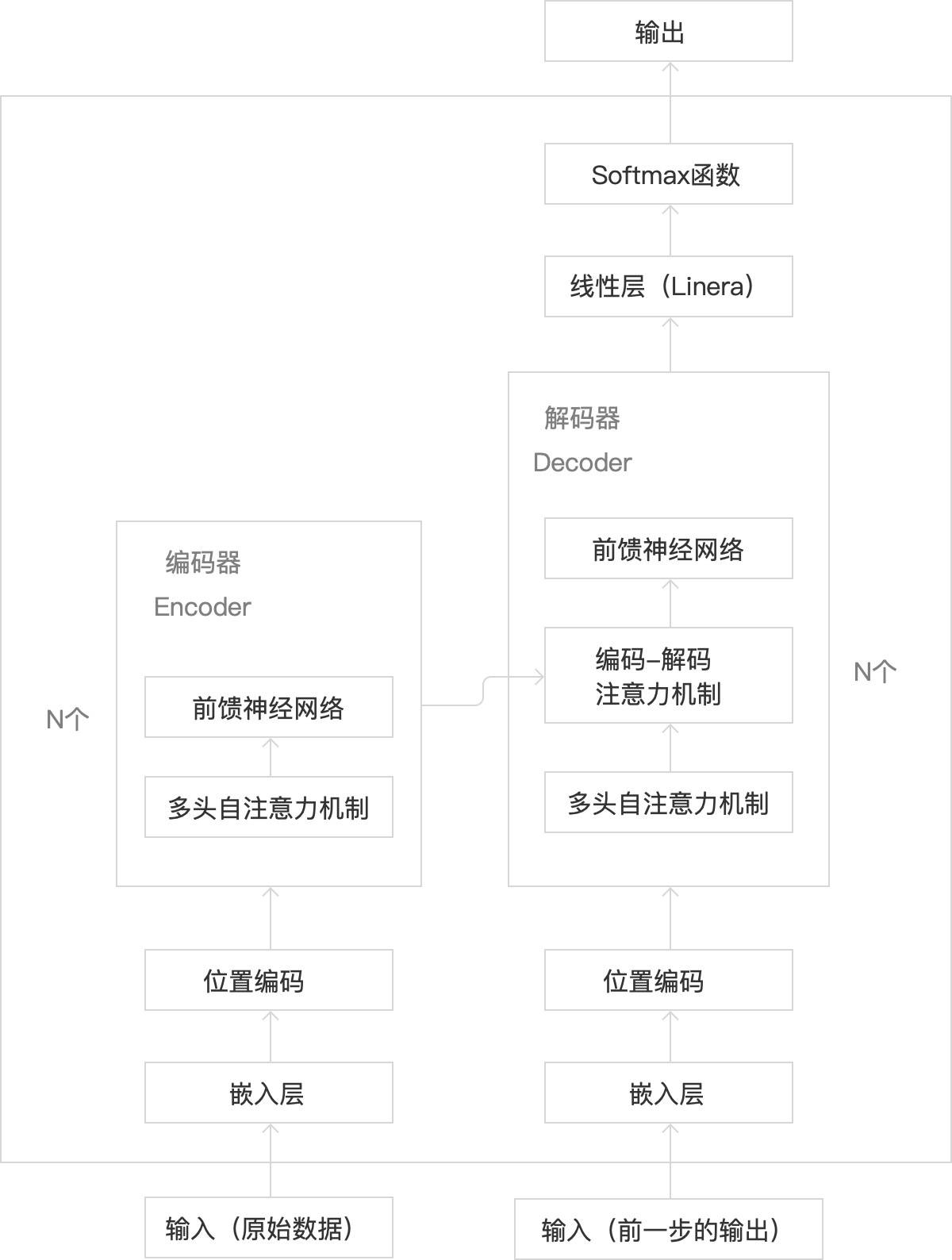
1)编码器及其输入/出部分:
i.输入:原始的海量数据
ii.嵌入层、位置编码:对原始输入数据进行处理
作用:将输入的词转化为向量,并加上位置信息,供编码器使用
iii.编码器内部:
多头自注意力:捕捉原始序列信息
前馈神经网络:增强模型表达能力
iv:输出:包含了原始输入信息的上下文信息与位置信息的向量序列,是后续解码过程的基础
2)解码器及其输入/出部分:
i.输入:分为2大部分
解码器自身的输入:
开始符号:表示输出序列的开头(作用:告诉解码器开始生成目标序列) 先前生成的词:指开始后,前一个时间步解码器的输出,也作为输入(作用:为下一步掩码多头自注意力机制提供实际内容,如上下文信息、位置信息等) 前一时间步:指在时间序列或序列数据中,当前元素(词、字符或时间点的数据)之前的那个元素或时间点 编码器的输出:编码器的输出作为解码器的输入(作用:编码器的输出综合了原始序列位置与上下文信息,来指导解码过程的注意力分配)
ii.嵌入层、位置编码:仅对解码器“先前生成的词”进行处理
作用:将输入的词转化为向量,并加上位置信息,供解码器中的多头自注意力机制使用
iii.解码器内部:
多头自注意力机制:详指带掩码的多头自注意力机制,针对已生成的输出序列(指前面说的“先前生成的词”被嵌入层与位置编码处理后的)进行处理,
(作用:防止未来的信息被利用,维护序列生成的因果顺序,确保模型生成目标序列时的连贯性与一致性)
(详细说明:和编码器中的有点不同,编码器中的会关注序列里所有其他词,但解码器中的只会关注当前词和它前面的其他词,后面的词会被遮住,确保解码器生成文本时,遵循正确的时间顺序)
·编码-解码注意力机制:捕捉编码器的输出与解码器即将生成的输出序列之间的复杂依赖关系,从而将原始序列的信息融合到输出序列的生成过程中(作用:有助于解码器生成准确的目标序列输出)
前馈神经网络:增强模型表达能力
iv.输出:一步步生成一个完整的输出序列
3)线性层与Softmax函数
i.线性层(Linera):主要用于对输入数据进行线性变换,调整数据的维度或简单的线性组合,转换维度;
ii.Softmax函数:主要用于将线性层的输出转换为词汇表的概率分布,选择最可能的输出序列(词汇表的概率分布代表下一个词(token)被生成的概率)。
线性层+softmax函数整体作用:把解码器输出的表示,转换为词汇表的概率分布(
从特征空间到最终输出结果的转换),从而进行词汇预测和生成任务。
3. Transformer与其他神经网络模型的对比
1)Transformer:基于自注意力机制的模型
能够高效处理序列数据
优点:
i.并行处理能力强:可并行处理整个序列,显著提高计算效率
ii.捕捉长距离依赖关系:能直接访问序列中的任意位置,有效捕捉长距离(上下文)依赖关系
iii.通用性强:能处理复杂任务,不仅适用于自然语言领域,还适用于图像处理等其他领域的序列建模任务
缺点:
i.资源消耗大:对于长序列处理时,计算和内存资源需求较高
ii.训练数据量要求高:通常需要大量的训练数据来获得良好的性能,特别是在处理复杂任务时
2)CNNs:卷积神经网络
主要适用于图像识别任务,提取图片的空间特征(图片中各部分之间的空间布局和相对位置,如连接、包含等关系)
优点:
i.空间特征提取能力强:无论图像如何移动,都能提取到相同的特征;
ii.参数共享和局部链接:减少模型参数数量,降低计算成本;
缺点:
i.无法处理序列数据:不适合捕捉长序列内的依赖关系;
ii.平移不变性:可能导致某些任务表现不佳
3)RNNs:循环神经网络
主要用于处理序列数据,能够捕捉数据中的时间依赖关系,适合处理如时间序列数据(如近3个月的股票价格数据、近一周的气温数据);
优点:
i.处理序列数据:擅长处理具有时间关系的序列数据,如文本、语音
ii.参数共享:在时间步上参数共享,减少了模型的参数数量
iii.短期记忆:能够记住短句子中前面的信息,理解上下文依赖关系
缺点:
i.长依赖问题:难以捕捉到远距离的时间依赖关系,如长句子中距离远的词,依赖关系无法捕捉;
ii.计算效率低:难以并行计算,导致训练速度较慢;
4)LSTM:是RNN的一种变体,长短期记忆网络
适合处理时间相关性较强的短序列数据;
优点:
i.处理长期依赖:有效处理序列处理中的长期依赖关系
ii.梯度问题:相比RNN,LSTM更好的解决了梯度消失/梯度爆炸的问题
缺点:
i.训练时间长:计算复杂度高,且难以并行
ii.资源消耗大:随着序列长度的增加,训练难度与资源消耗也会增加
4. 应用现状
在Transformer原始架构的基础上后续出现了变种:
主要分为3类:
1)仅编码器:如 Bert,适用于理解语言的任务,如掩码语言建模(让模型猜被遮住的词是什么)、情感分析(让模型猜文本情感是积极还是消极)等
2)仅解码器:如GPT系列(ChatGPT),擅长通过预测下一个词,来实现文本生成等
3)编码器+解码器:如T5、BART,适用于把一个序列转换成另一个序列的任务,如翻译、 总结等








 京公网安备 11011402013531号
京公网安备 11011402013531号