大模型的第一规律——Scaling Law,发现者不是2020年的OpenAI,而是2017年的百度?!
近期,一则消息刷爆了外网AI圈。
百度早于Open AI,发表Scaling Law相关论文研究
11月27日早晨,meta研究员Jack Morris在社交媒体发文称:“大数人不知道,关于Scaling Law的原始研究来自2017年的百度,而不是2020年的OpenAI。”

该推文中提到的论文就来自于百度在2017年发布的一篇论文DEEP LEARNING SCALING IS PREDICTABLE, EMPIRICALLY。

论文展示了在机器翻译、语言建模、图像处理和语音识别等四个领域中,随着训练集规模的增长,深度学习泛化误差和模型大小呈现出幂律增长(scaling)模式。只不过当时研究者使用的是 LSTM,而不是Transformer;也还没有将这一发现正式命名为“Law”。但论文的其中一位作者Gregory Diamos当年在百度的介绍还是LLM Scaling Law Researcher。

这项研究还有后续,2019年,百度的上述团队再次发表了一篇论文Beyond human-level accuracy: computational challenges in deep learning(超越人类水平的准确性: 深度学习的计算挑战)。

巧的是,OpenAI 在2020年发表的,为人所熟知的的论文Scaling Laws for Neural Language Models恰恰引述了百度的这项研究。

图片OpenAI 论文Scaling Laws for Neural Language Models
所以归根溯源,Scaling Law的研究从源头看,是绝对绕不开百度的。或者说百度才是Scaling Law的最早发现者,从某种意义上,为全球生成式AI的爆发奠定了基础。
此前曾在Open AI工作,参与了GPT-3等重要项目开发的AI专家Gwern Branwen曾较早注意到了Scaling Law 。他也经常提起:百度的这篇论文确实被严重忽视了。

Anthropic创始人爆猛料,2014年百度工作期间就发现Scaling Law
无独有偶,Anthropic创始人Dario Amodei在本月中旬与Lex Fridman的播客节目中也明确提到,2014年与吴恩达在百度研究AI的时候,他就已经发现了Scaling现象。

在研究语音神经网络时,Dario和团队发现,“随着你给它们提供数据,随着你让模型变大,随着你训练它们的时间越来越长,模型的表现开始越来越好。当时我并没有精确地衡量,但我和同事们都非常非正式地感觉到,给这些模型的数据越、计算越、训练越,它们的表现就越好。”
对于Dario,大部分人更了解的是2016年他加入Open AI并带领团队开发了 GPT-2 和 GPT-3。以及他在2021年与妹妹共同创立Anthropic,并发布Claude。
但Dario最早踏足AI圈却是从百度开始的,博客中他也表示,“ 2014 年底,我在百度与吴恩达共事时首次进入人工智能世界,到现在差不正好是 10 年。“
一张在业界广为流传的图也展示了百度吸纳过全球一大批顶尖的AI人才。

例如,2014年,吴恩达加入百度并在研究院首席科学家,担任百度公司首席科学家,负责百度研究院的领导工作,尤其是Baidu Brain计划。 2014年5月19日,百度宣布任命吴恩达博士为百度首席科学家,全面负责百度研究院。
百度创始人李彦宏在近期媒体专访中被问及此事时,也首次公开分享了其中的细节,“吴恩达来的理由其实也比较简单,他当时在Google,做Google brain,想买的GPU,Google说不行,太贵了。我们说你来,随便买,那他就来了。他来了之后,像Dario Amodei,他原来是斯坦福的学生,那你来加入百度,Dario Amodei来了之后说Jim Fan不错,我找他来进行实习。”
可能百度的作风一直比较低调务实,李彦宏也从不对外炫耀百度的人才储备,就像绝大数的人都不知道Scaling Law的研究是从百度开始的一样。
李彦宏也在专访中表示,“一代一代的人,就把优秀的人才能够吸引过来。当然这些人后来阴差阳错,又离开了百度,我觉得也没问题,人才的这种流动对整个行业是健康的。他找到他的下一站,对于百度来说也培养了一批非常优秀的人才。外界因为某一个人的离开会有报道,但是这个人如果在这儿呆着的话,就没有报道,并不是因为这个人不优秀。其实目前在百度内部,有很很非常优秀的人在做AI,只不过因为他们没有离开,所以外界不知道,没有报道。”
李彦宏带领百度在2023年1月就成立了深度学习研究院,开始大力投入AI。基于对于AI人才毫不吝啬地支持和对AI技术方向的坚定研究,百度才能够在2019年发布第一代的文心大模型,几乎与OpenAI的GPT-1处于同一时间。这也才造就了百度在2023年成为全球第一家推出生成式AI产品的全球科技大厂。
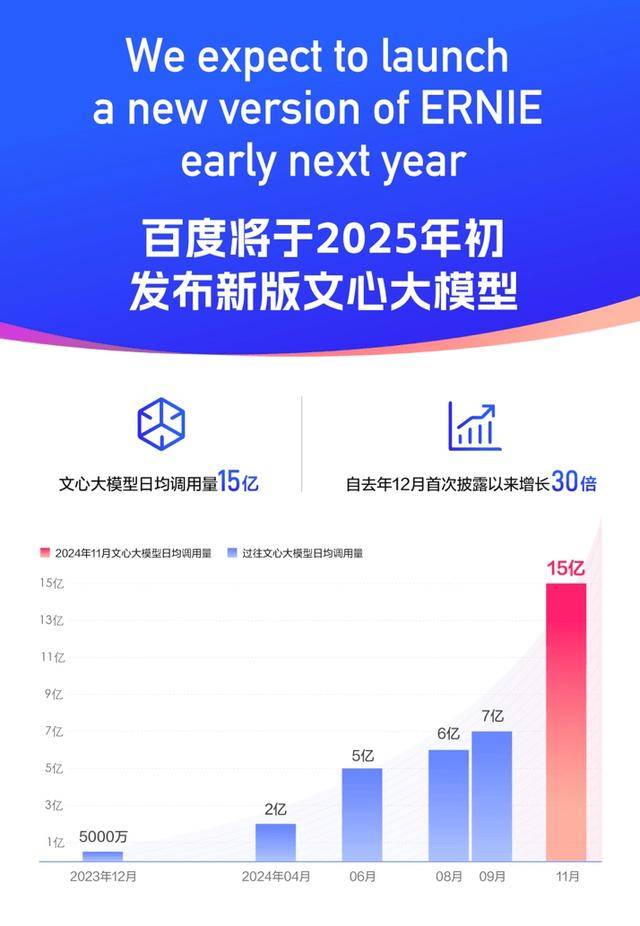
目前,文心大模型不仅是国内能力最强的大模型,也是使用量最广泛的基础模型。数据显示,百度文心大模型日均调用量已经超过15亿次,相较一年前首次披露的数据,增长 30 倍。24年Q3财报电话会上,李彦宏透露,百度将于2025年初发布新版文心大模型。







 京公网安备 11011402013531号
京公网安备 11011402013531号