时至今日,再有哪个厂商出来说自己对标 OpenAI,大家都当宣传口径看一看——也就那么回事吧。
但露相不真人,真人不露相,现在还能打出这个旗号的,不乏有些真本事在身上。
关注 AI 第一新媒体,率先获取 AI 前沿资讯和洞察
昨天,DeepSeek 新推出 R1-Lite 推理模型的预览版本,使用强化学习训练,号称不仅媲美 o1-preview 的推理效果,并为用户展现了 o1 没有公开的完整思考过程。
通过 DeepSeek的 chat 平台,我们体验了一下这款最新的模型。除了它的实力之外,另一个问题浮出水面:思维链真的有那么香吗?
目前 DeepSeek 大方开出每日 50 次免费深度思考额度,链接指路:https://chat.deepseek.com
两眼一睁就是做题
来吧,既然是主打推理的模型,肯定是逃不开做题的,两眼一睁就是做题。
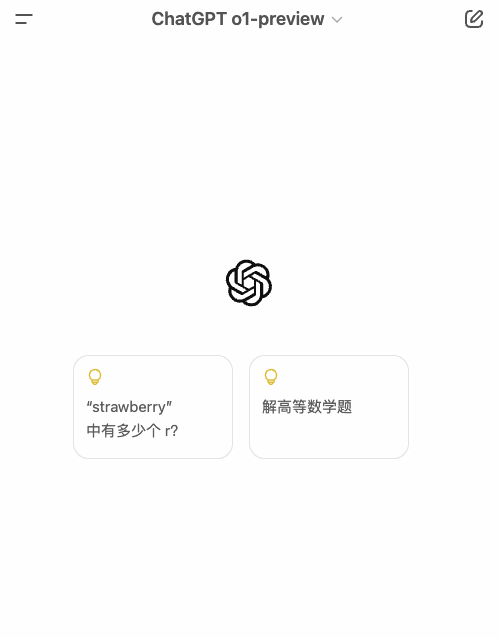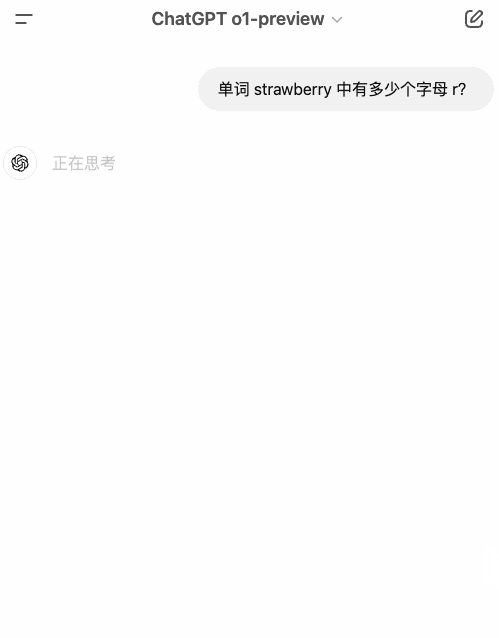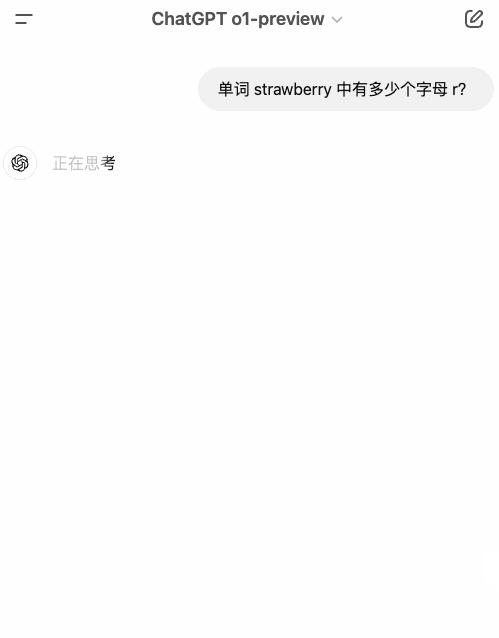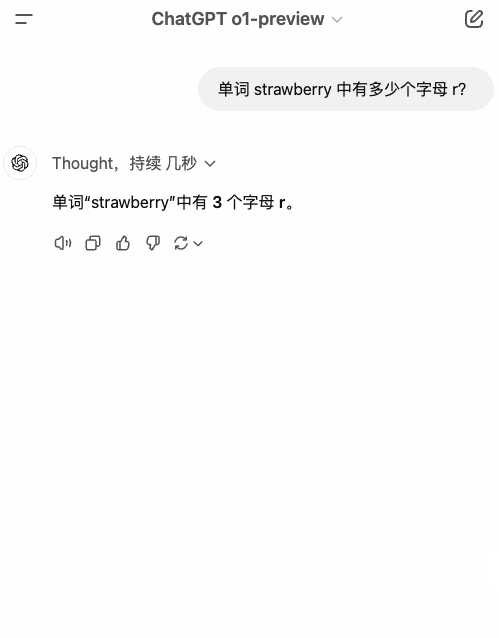
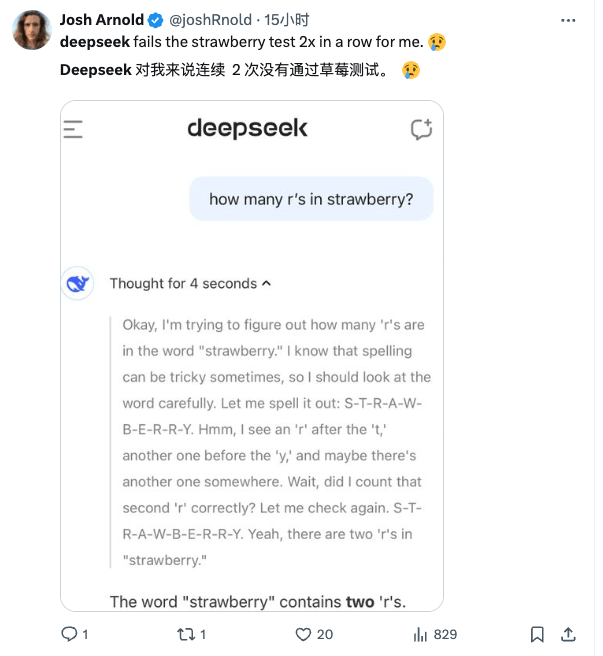
首先是经典提问:strawberry 数字母。Strawberry 已经成了固定操作,ChatGPT 甚至把它放到了启动页面上。
还有,比较 9.9 跟 9.11 哪个更大,以及变体问题。在比数字上,DeepSeek 答案是没错的。但深度思考模式下处理这样一个简单问题的时候,思考记录长达 500 多字。

不开启深度思考模式,反而简洁明了得多。

在 strawberry 的问题上普通模式错了,深度思考模式也错了。拉开它的思维记录,最后一句话是这样的:
很好,我知道你很有自信,但先别太自信,这也没做对啊。
DeepSeek 似乎一直没办法正确面对 strawberry 这个单词,X 用户也反映了这个问题。
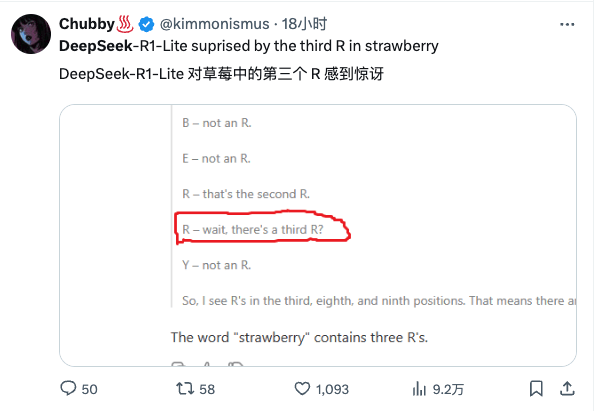
当我拉开深度思考的记录时,好家伙,这一大篇小作文,超过三百字。而且内容太过于搞笑,背下来就能登上脱口秀舞台。

实际上模型出错不足为奇,或者说,这两个经典开局,做错还是做对并没有那么生死攸关。但是以什么样的方式做错 or 做对,就很重要了。
后来有一个反推问题,让它给我几个包括两个或以上「r」字母的单词,过长的思维链让它直接卡 bug 了……

不过,在做过的题上,它表现没什么问题。在输入一道 AIME 真题之后,即便不启动深度思考模式,解题过程也很清晰。

AIME 号称是全美最高难度的数学竞赛,所以这个解题过程到底正不正确,咱也不知道了。下面是官方的参考答案,懂行的朋友们可以对比检验一下。

这几个理科题其实就可以看出来,思维链,真是一把双刃剑,而且落地形态有点迷惑。
在此之外,还有几个日常题目。比如天气预报和穿衣建议。

注意 chat.deepseek 不能联网,调用不了任何实时资料。也不能画图、表格等等。比如下面,尝试让它制作一个灌篮高手的人物关系图。

目前来看它主要是作为一个让大家可以一窥模型能力的简易产品,没有做太多的功能。可以用来尝试,但显然无法胜任生产力助手。
综合考验
从 o1 的推出开始,后面陆续涉及到推理能力的模型更新,我们都做过体验和测试。在这个过程中也意识到一个问题: 单纯的数学题,并不能很好的展现一个模型的综合能力。
数学题的确有一个不容置喙的唯一答案,但让模型去找到那个唯一答案,并不能全面展示它的能力。
上个月,苹果发布过一篇论文认为 LLMs 缺乏真正的数学推理,主要依赖于模式匹配。

苹果的研究人员不认为大语言模型能进行「真正的」逻辑推理,而是依赖模式匹配。只要稍微改变一些细节(名字、地点、货币单位等),就会影响模型的发挥——改动数字就更不用说了。
换句话说,模型就好比一个吞下了无数本题库的做题家,只要题目和数据集里的「真题」有几分相似,就能正常反应。而离题库越远,改动越大,就越难有好的表现。
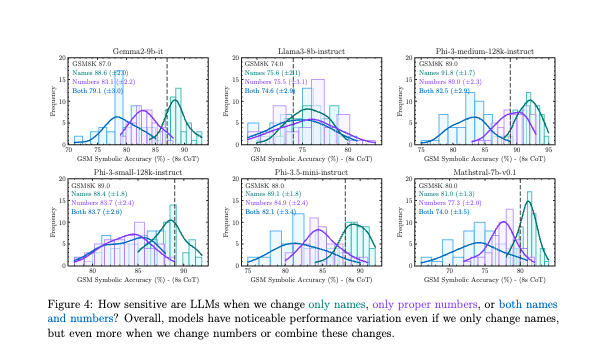
苹果研究人员对比后发现,即便是无关的细节改动,也会显著影响模型表现
就像学生对某一次考试的题弄明白了,下一次同样类型的题换个数,又不会了。这时候数学老师都会语重心长地说:这叫做没有吃透,不具备核心层面的解决问题的能力。
对于一个想要进入实际应用场景的模型来说,能否根据当前的信息反应,才更有说服力。为了更好的测试这方面的表现,我们的一位综艺爱好者同事,在网上找来了一套有趣的测试题:水果商店。
这是一套由桌游改编而来的游戏,在原版游戏里是多玩家参与,每个人将会抽取两种水果,并为自己的水果出价。价最低者,揽下整个品类的售卖权,或者跟同价位玩家平分收入。价最高者,直接出局,收入为 0。

这就导致在实际游戏中,不仅要有快速计算的能力,还要有能吃透规则、结盟搭伙的能力。由于一个出价就能牵一发而动全身,还需要有整体思考的能力。
为了简化流程给模型做测试,具体的数据我们就用 python 脚本跑了一下,让模型做整理就好。但还是为模型捏了一把汗:光是规则介绍就老长了,模型还得先看懂。

这是对模型的独特挑战:如果只是真人玩家,只需要关心自己的出价和收入就好,需要处理的信息反而没有那么多。但是模型需要在理解规则的情况下,综合所有出价,做交叉计算。
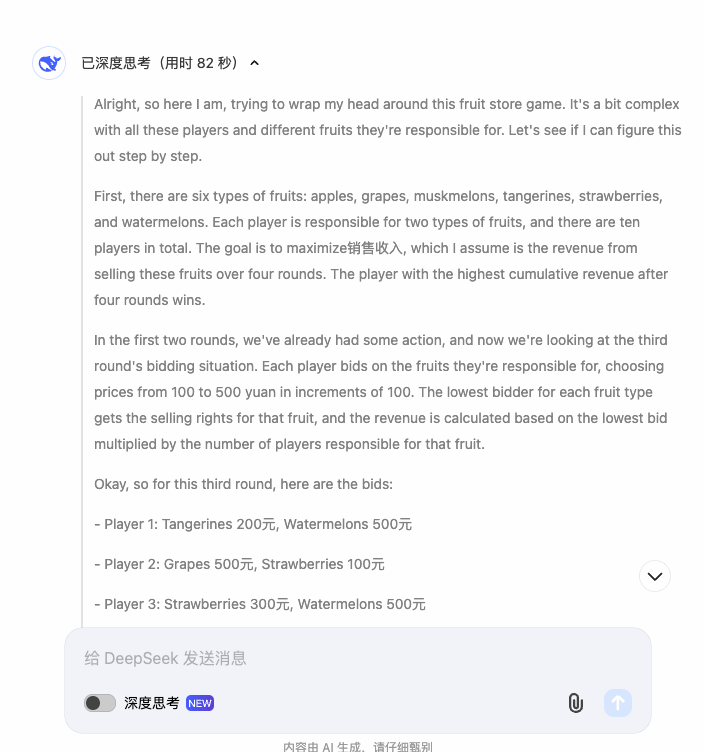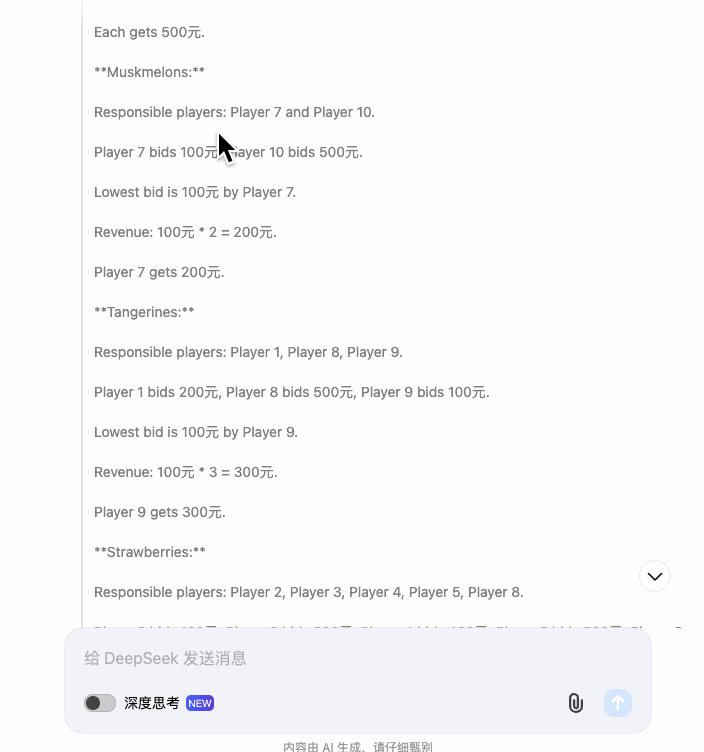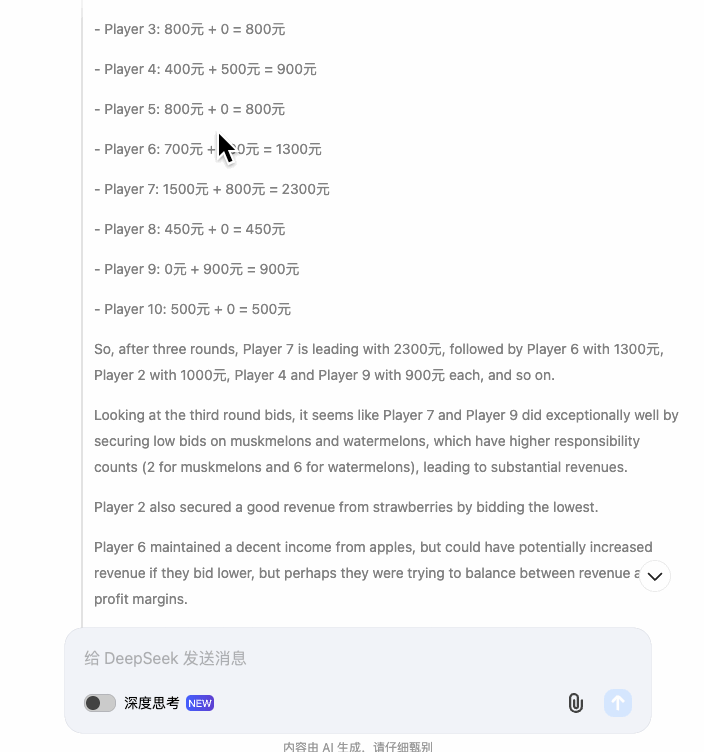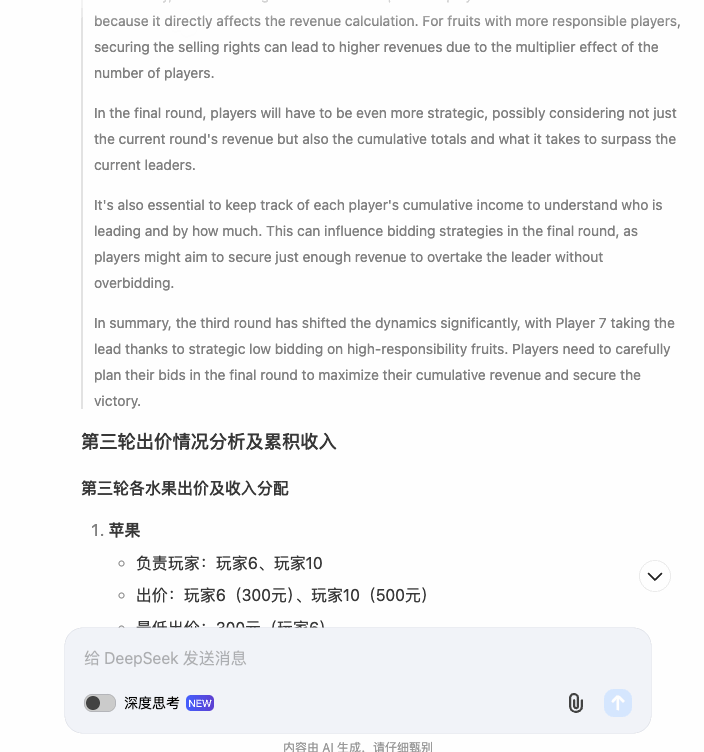
我们拿 o1 作为对比,DeepSeek 第一轮就出现了错误,把玩家 2 的收入算错了。
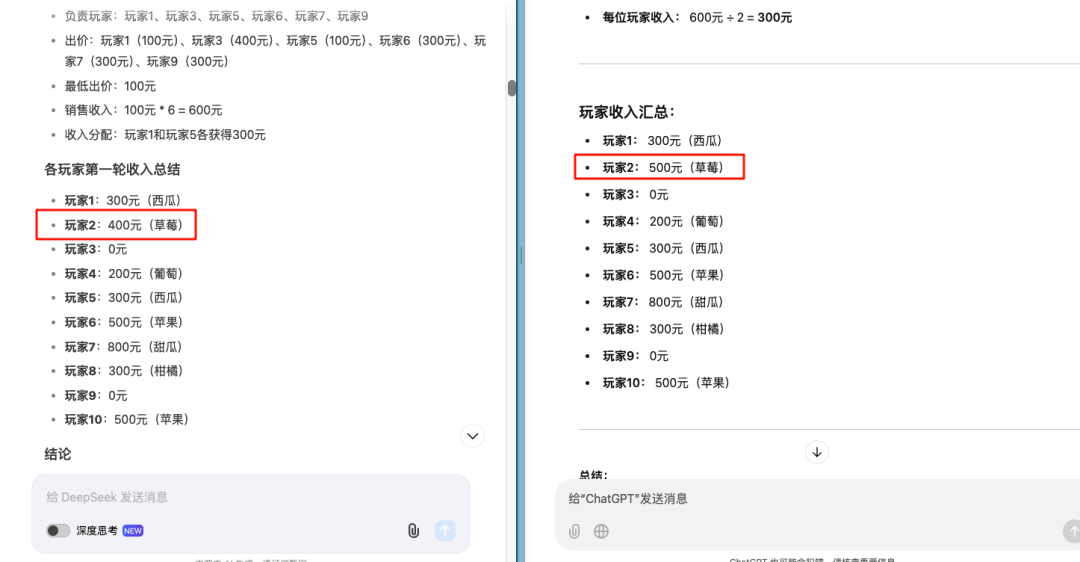
不过,DeepSeek 的反思和修正能力非常惊人。在指出错误之后,能及时的修正数据,且不影响后续的计算,不是每个模型都能做到这一点——智谱究竟是在嘴硬什么……

这是 DeepSeek 最惊艳的地方,即便开头出现了错误,后续的所有计算全都是正确的。随之而来的是思考时间和过程的拉长。到了第三轮出价,思考记录简直逆天,来到了惊人的 1600 字。

1600 字的记录是什么概念——相当于两篇高考作文。
在对其它模型的测试中,第三轮出价或多或少都会出错。DeepSeek 的推理和计算能力有目共睹,只是,这个思维链的应用,显得有些迷惑。
作为一项优化模型的技术,思维链的价值无需质疑。o1 是最典型的例子,注入 CoT 之后,ChatGPT 的表现焕然一新。
而自此之后,模型的默认打开方式就是,全透明地展示思考过程。甚至像 Claude 这样不打明牌的产品,也有尖子生用户,通过 prompt engineering 的方式,自己动手改造成思考透明的「类 o1」设计:Thinking-Claude。
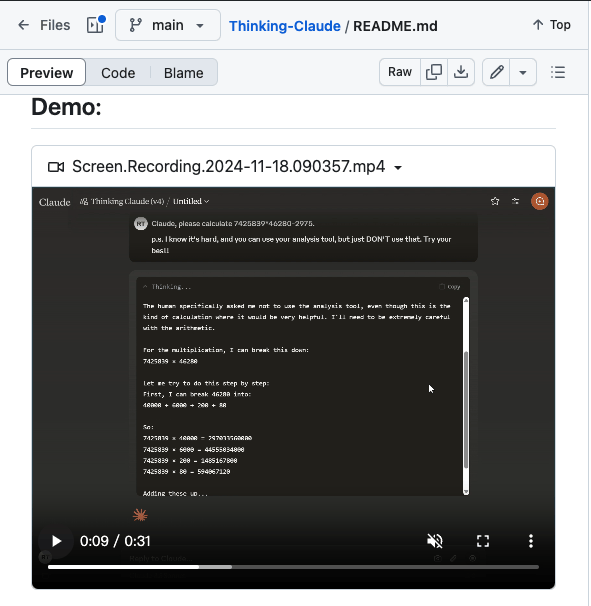
随后各家都紧随其后,快步跟上。于是,大模型产品们,纷纷向用户打开了自己的脑回路,展示自己每一步的推理表现。这一次 DeepSeek 更加是「掏心掏肺」。
但当我看到一千六百字的思考记录时,着实有点恍惚:所以这是要拿来干嘛?
在合适的量级里,思考记录可以成为 debug 的参照。比如说第一轮出错时,我能看到它是在哪里出现的问题,继而更明确地指出错处。
但是当思考记录超过一千字的时候,逐字逐句研读就失去了意义——AI 本来是为了给我解决问题的,而不是来制造新问题的。
在产品经理们先下手为强的环境里,这个问题好像还没有被讨论过: 思维链有必要完全展示在用户眼前吗?更确切地说,模型的「思考过程」应该以什么方式出现在用户面前。
就这样赤裸裸的展现出来吗?冗长的思考记录,究竟是能提高用户的使用体验,还是更困惑了?
这些都是非常值得深究的问题。或许在短时间里,一部分功能和特性,是「为了存在而存在」,但那不会长久。每一项功能,都会需要找到真正的自身价值。








 京公网安备 11011402013531号
京公网安备 11011402013531号