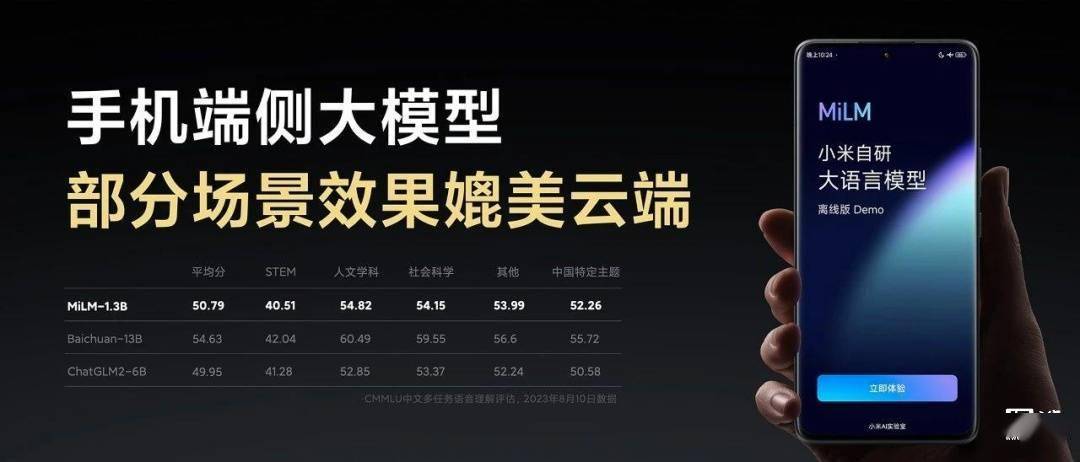
11 月 12 日消息,小米公司 MiLM 大模型在去年 8 月首度现身 C-eval、CMMLU 大模型评测榜单,并在今年 5 月通过大模型备案,相关模型逐步应用于小米汽车、手机、智能家居等产品中。
今日,小米官方宣布大模型已经实现了从一代到二代(MiLM2)的升级迭代。
据介绍,此次迭代不仅扩充了训练数据的规模、提升了数据的品质,更在训练策略与微调机制上进行了深入打磨,增强了技术实力并全面升级了配套的部署技术。从小米公告获悉,小米第二代大语言模型的几个主要升级是:
第二代大语言模型丰富了模型的参数矩阵,参数规模同时向下和向上扩充,实现了云边端结合,参数尺寸最小为 0.3B,最大为 30B;
第二代大语言模型在 10 大能力维度上,相比于第一代模型平均提升超过 45%,其中指令跟随、翻译、闲聊等对于智能助手而言比较关键的能力上,效果处于业界前列;
第二代大语言模型在端侧部署上支持 3 种推理加速方案,包括大小模型投机、BiTA、Medusa,并且自研量化方案相比于业界标准高通方案,量化损失降低 78%;
第二代大语言模型支持的最长窗口为 200k(第一代为 4k),在长文本评测中,效果处于“业界前列”。
二代效果全方位提升小米大模型团队采用自主构建的通用能力评测集 Mi-LLMBM2.0,对最新一代的 MiLM2 模型进行了全方位评估。
该评测集涵盖了广泛的应用场景,包括生成、脑暴、对话、问答、改写、摘要、分类、提取、代码处理以及安全回复等 10 个大类,共计 170 个细分测试项。
以 MiLM2-1.3B 模型和 MiLM2-6B 模型为例,对比去年发布的一代模型,在十大能力上的效果均有大幅提升,平均提升幅度超过 45%。
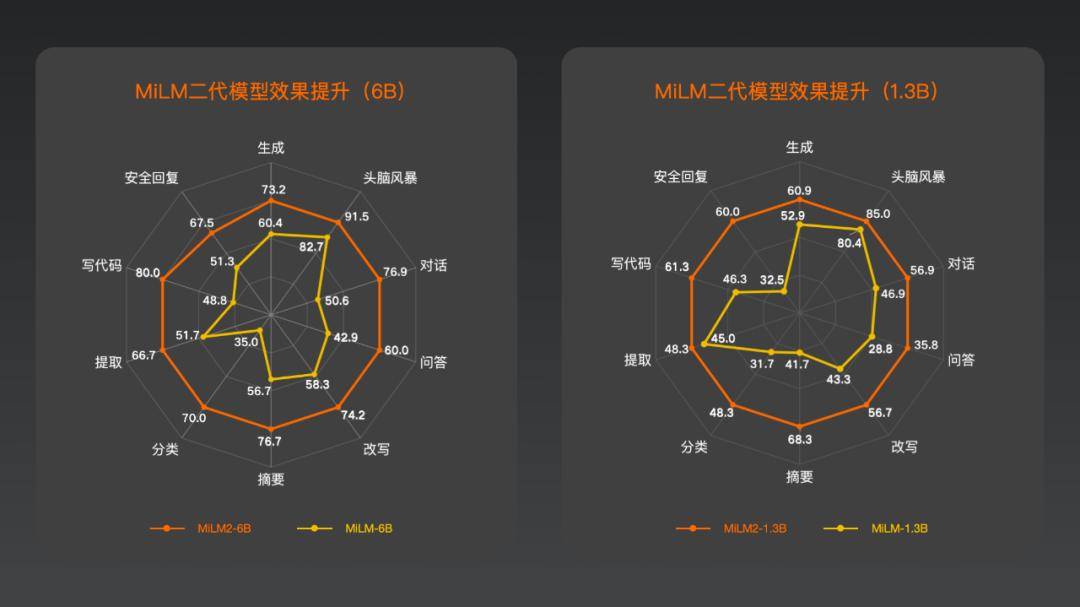
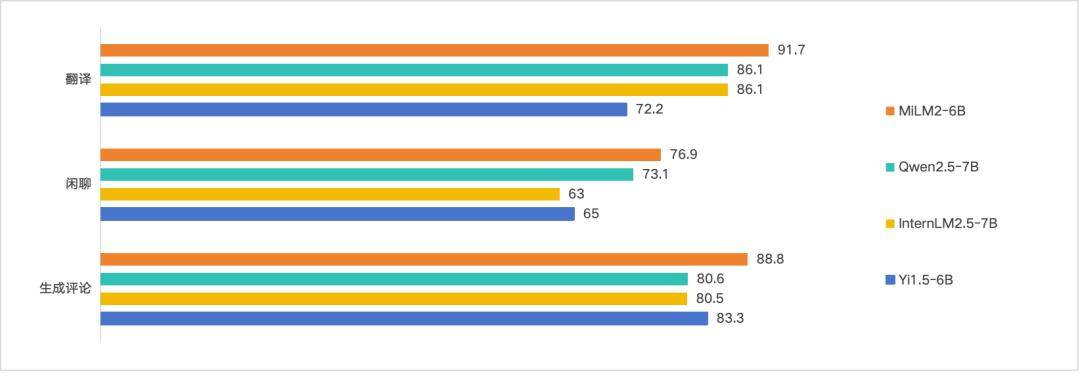
小米的「人车家全生态」战略,旨在构建一个涵盖人、车、家等多元化生活场景的超级智能生态系统,对于大模型的生成、闲聊、翻译等能力提出了更高的要求。在这些关键能力上,MiLM2-6B 模型的评测成绩号称“对比业内同参数规模模型也有较优的效果”。
MiLM2 模型矩阵云边端结合
在轻量化部署的大原则下,小米自研大模型团队考虑了集团内部多元化的业务场景及不同落地场景的资源限制,构建并不断扩充了自研大模型的模型矩阵,将大模型的参数规模扩展至 0.3B、0.7B、1.3B、2.4B、4B、6B、13B、30B等多个量级,以适应不同场景下的需求。
0.3B~6B:终端(on-device)场景,应用时通常是一项非常具体的、低成本的任务,提供不同参数规模的模型以适配不同芯片及存储空间的终端设备,微调后可以达到百亿参数内开源模型效果。
6B、13B:在任务明确、且需要比 6B 以下参数模型提供更多的零样本 zero-shot / 上下文学习时,6B 和 13B 是一个可能有 LLM 涌现能力的起点,支持多任务微调,微调后可以达到几百亿开源模型的效果。
30B:云端场景,具备相当坚实的 zero-shot / 上下文学习或一些泛化能力,模型推理能力较好,能够完成复杂的多任务,基本达到通用大模型水平。
小米自研大模型矩阵不仅包含多样的参数量级,同时也纳入了各种不同的模型结构。在二代模型系列中,大模型团队特别加入了两个 MoE(Mixture of Experts,即混合专家模型)结构的模型:
MiLM2-0.7B×8
MiLM2-2B×8
两个模型的差异主要体现在训练总参数量、词表大小等方面。MoE 模型的工作原理是将多个承担特定功能的“专家”模型进行并行处理,进而综合各模型的输出来提高整体预测的准确度和效率。
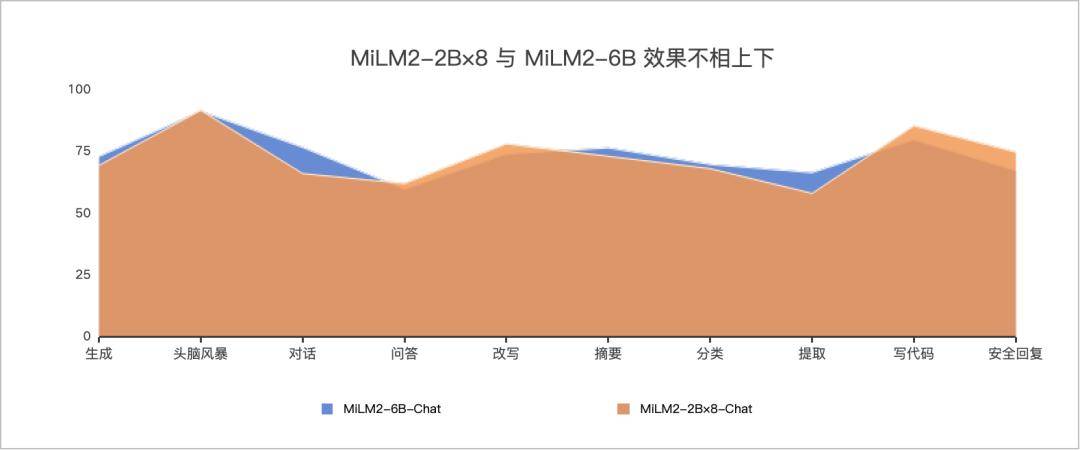
以 MiLM2-2B×8 为例,根据评测结果,该模型在整体性能上与 MiLM2-6B 不相上下,而解码速度实现了 50% 的提升,在保证模型性能不打折扣的同时,提升了其运行效率。
4B 模型端侧落地,30B 模型云端部署端侧新增 4B 模型
去年,小米的大模型团队在端侧部署方面取得了进展,使小米成为业界首个在移动设备上成功运行 1.3B 和 6B 大模型的公司。随着二代大模型的迭代更新,端侧部署技术也有了新的突破,新的 4B 模型将在端侧发挥更重要的作用。
小米大模型团队地提出了“TransAct 大模型结构化剪枝方法”,用 8% 的训练计算量即从 6B 模型剪枝了 4B 模型,训练效率得到提升;同时小米大模型团队自研了“基于权重转移的端侧量化方法”和“基于 Outliers 分离的端侧量化方法”,降低了端侧量化的精度损失,对比业界标准高通方案,量化损失下降 78%。MiLM2-4B 模型总共 40 层,实际总参数量为 3.5B,目前已经实现在端侧部署落地。
Qwen2.5-3B-Instruct 结果采用 FollowBench 和 IFeval 官方代码测试云端新增 30B 模型
MiLM2-30B 模型是小米二代大模型系列中参数量级最大的模型,专为云端场景设计。
在云端环境中,大模型面临着多样化和高难度的挑战,需要更高效地遵从并执行用户的复杂指令,深入分析多维度任务,并在长上下文中精准定位信息。针对这些重点目标,大模型团队选择了一系列开源的评测集,对 MiLM2-30B 模型的专项能力进行评估。
结果表明,MiLM2-30B 模型在指令遵循、常识推理和阅读理解能力方面表现出色,具体的评测集和评测结果如下:
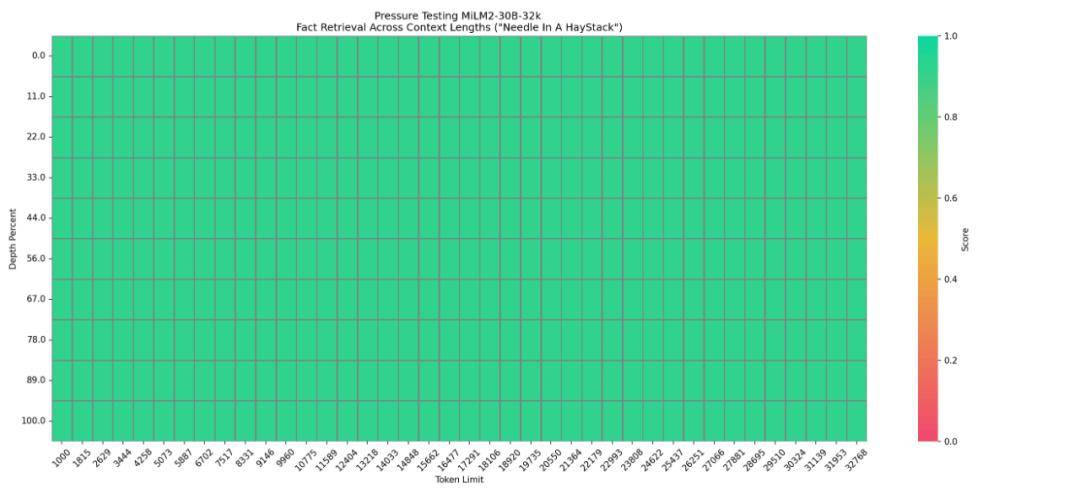
小米公司表示,小米第二代自研大模型取得的进步和成果,已经开始渗透到真实的业务场景与用户需求中,不仅帮助集团内部解决了多样化的业务需求、实现工作提效,也已经在澎湃 OS、小爱同学、智能座舱、智能客服中开始应用落地。








 京公网安备 11011402013531号
京公网安备 11011402013531号