11月8日,智谱推出新清影:10s时长、4k、60帧超高清画质、任意尺寸,自带音效,以及更好人体动作和物理世界模拟。
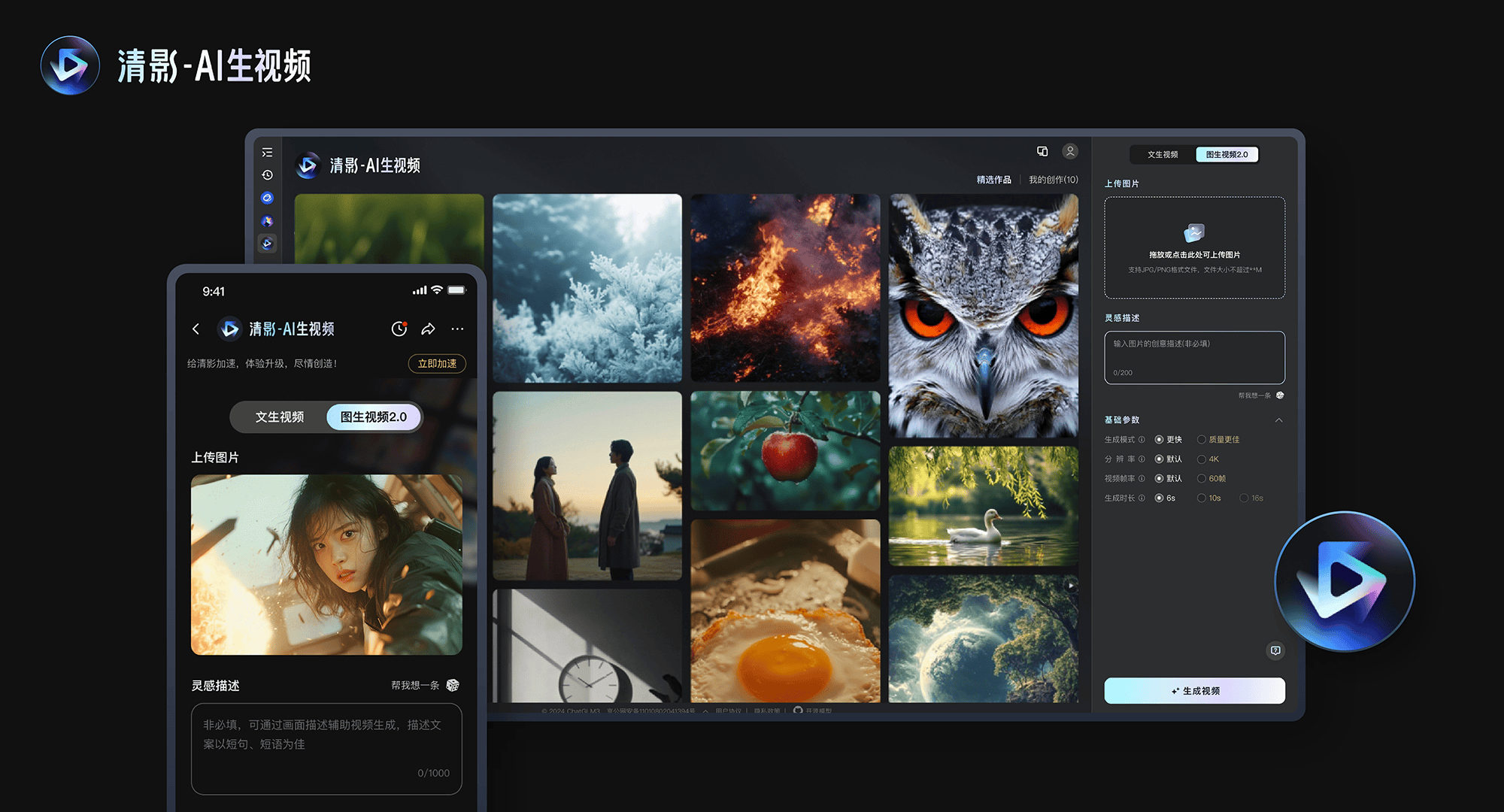
3个月前,作为国内首个面向公众开放的视频生成产品,清影上线清言App,只需一段指令或图片,30秒就能生成AI视频。为人类影视创作带来了更多创新玩法,如广告制作、短视频、表情包梗图等。
清影发布后不久,GLM技术团队先后开源了CogVideoX 2B和5B版本两个模型,可在消费级显卡上流畅运行,性能领先的CogVideoX-5B模型自开源以来受到广泛的关注,并衍生出如CogVideoX-factory等大量的二次开发项目。
基于CogVideoX模型的最新技术进展和智谱最新推出的音效模型CogSound,新清影在以下5个方面实现了提升。
· 模型能力全面提升:在图生视频的质量、美学表现、运动合理性以及复杂提示词语义理解方面能力明显增强。
· 4K超高清分辨率:支持生成 10s、4K、60帧超高清视频,视觉体验拉到极致,动态画面更加流畅。
· 可变比例:支持任意比例的图像生成视频,超宽画幅也能轻松Hold住,从而适应不同的播放需求。
· 多通道生成能力:同一指令/图片可以一次性生成4个视频。
· 带声效的AI视频:新清影可以生成与画面匹配的音效了。音效功能将很快在本月上线公测。
即日起,新清影在智谱清言App上线,为了支持广大开发者,智谱同时将CogVideoX v1.5-5B、CogVideoX v1.5-5B-I2V进行了开源。
生成视频将为影视工作者、短视频创作者提升产量、产能,在其生产流程中发挥重要作用。不到一年时间,生成视频技术在视频时长、生成速度、分辨率、一致性等方面已经显示出长足进步。新清影往前又迈进了一步,未来,智谱也将携手视觉中国等合作伙伴,基于更丰富的视觉内容,产出更好的AI生成视频工具。
“默片 Sora”进入“有声电影时代”
智谱认为真正的智能一定是多模态的,听觉、视觉、触觉等共同参与了人脑认知能力的形成,因此,智谱希望包括文字、图像、语音和视觉等模态在内的智谱多模态大模型矩阵,能够进一步提高大模型的应用和工具能力。

因此,GLM模型家族逐步从文字拓展至图片、视频、声音,以及音效。今天,GLM家族加入了新成员——音效模型CogSound和音乐模型CogMusic。即将上线与大家见面的音效模型CogSound能根据视频自动生成音效、节奏等音乐元素,它是基于GLM-4V的视频理解能力,能够准确识别并理解视频背后的语义和情感,在此基础上生成与之相匹配的音频内容,甚至生成复杂音效,如爆炸、水流、乐器、动物叫声、交通工具声等。
音效模型的出现能够实现视频与声音的同步创作。同时该模型在电影行业也具有广泛的应用前景,比如可以生成电影中的大规模战斗场景和灾难场景的声音,大大缩短了制作周期,降低了制作成本。
「CogVideoX + CogSound」由清影生成画面,音效模型配音
两周前,智谱刚刚发布最新的GLM-4-Voice情感语音模型。今天,随着音效模型的加入,GLM大模型在声音模态领域实现了人声、音效、音乐的多链路布局,基于图像、视频和声音的多模态模型矩阵由此更加完整,意味着智谱在多模态和工具两个维度上都朝着AGI的目标迈出了一小步。
音效模型将于本月上线清言App,与新清影一起生成有声AI影片。智谱的理想状态是,只需一个好的创意,剩下的事AI都能辅助搞定,轻松将一个idea、一张图,变成一段自带bgm的影片。相信这个组合能给创作者和用户带来AI生视频的全新体验。
当前,AI生成视频用于影视创作仍需要多种不同的创作工具串联使用。但基于智谱多模态的最新成果,实现这种一站式AI原生多模态工作流,这样的前景无疑是激动人心的。






 京公网安备 11011402013531号
京公网安备 11011402013531号