十几个小时之前,加州大学欧文分校(UCI)的物理学博士Kyle Kabasares,实测chatGPT o1 preview+mini后发现:自己干了大约1年的博士代码,o1竟在1小时内完成了。
不信?那就让我们看视频,眼见为实。
chatGPT不仅能写视频,还可以理解视频,帮我们生成视频摘要(见下图右边):
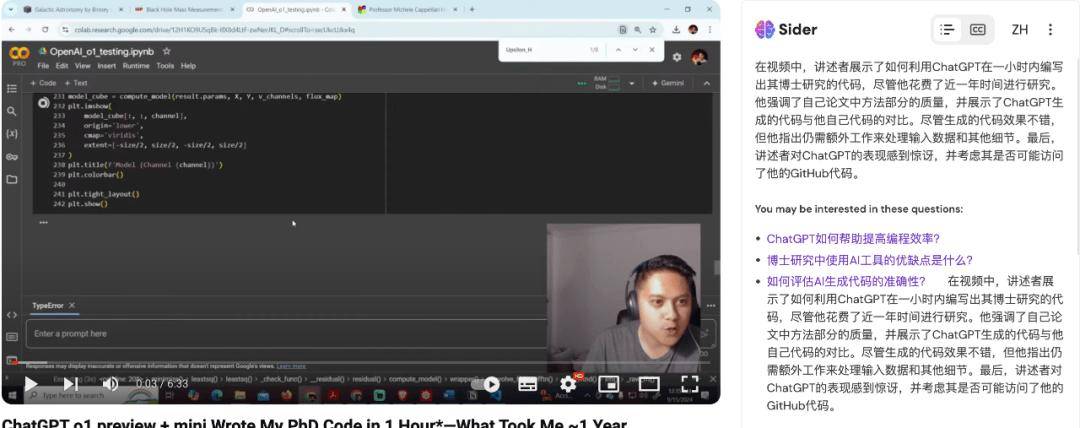
下面就是为这个视频生成的解说词:
在视频中,讲述者展示了如何利用ChatGPT在一小时内编写出其博士研究的代码,尽管他花费了近一年时间进行研究。他强调了自己论文中方法部分的质量,并展示了ChatGPT生成的代码与他自己代码的对比。尽管生成的代码效果不错,但他指出仍需额外工作来处理输入数据和其他细节。最后,讲述者对ChatGPT的表现感到惊讶,并考虑其是否可能访问了他的GitHub代码。
You may be interested in these questions:
ChatGPT如何帮助提高编程效率? 博士研究中使用AI工具的优缺点是什么? 如何评估AI生成代码的准确性? 在视频中,讲述者展示了如何利用ChatGPT在一小时内编写出其博士研究的代码,尽管他花费了近一年时间进行研究。他强调了自己论文中方法部分的质量,并展示了ChatGPT生成的代码与他自己代码的对比。尽管生成的代码效果不错,但他指出仍需额外工作来处理输入数据和其他细节。最后,讲述者对ChatGPT的表现感到惊讶,并考虑其是否可能访问了他的GitHub代码。You may be interested in these questions:
ChatGPT如何帮助提高编程效率? 博士研究中使用AI工具的优缺点是什么? 如何评估AI生成代码的准确性?亮点
展开全部
00:58
这段对话展示了一个人对自己编写的代码感到惊讶和骄傲。他对比了另一篇论文的研究方法,强调了自己方法部分的质量和简洁性,认为很多论文的研究方法写得很糟糕。
折叠
00:44
在讨论中,他提到自己的代码如何使用合成数据和自身功能,表明代码的执行效果令人印象深刻。这显示了他对自己工作的认可和自信。
01:16
他表达了对研究方法部分写作质量的自豪,指出许多研究论文的写作水平较低。这种对比突显了他在学术写作方面的能力和对高质量工作的追求。
01:41
他提到的215行代码中包含许多可视化元素,表明他在数据展示上的努力和创意。这种可视化不仅增强了结果的可理解性,也展示了研究的深度。
02:11
在视频中,讨论者提到他们在编写代码时没有给出实际的示例代码,而是只提供了论文中的描述。这种方法需要多次提示,但最终得到了想要的结果,显示了生成代码的潜力。
折叠
02:18
讨论者提到自己进行了多次尝试,估计提示的次数达到六到七次。这种反复的试验过程展示了与人工智能沟通时的复杂性与挑战。
03:09
他们的代码没有直接展示,而是通过描述来引导人工智能生成代码。这种方法强调了描述性语言在程序设计中的重要性。
04:01
最终,讨论者成功生成了所需的功能代码,体现了人工智能在编程上的应用潜力。这不仅提高了开发效率,也改变了传统编写代码的方式。
04:20
在机器学习模型的使用中,输入数据的质量和处理方式至关重要。尽管模型能够生成某些结果,但仍需额外的软件和工具进行处理,以确保结果的准确性和有效性。
折叠
04:38
使用合成数据进行模型测试是常见的做法,但仍需关注数据的噪声和边缘效应。这些因素可能会影响模型的最终输出,因此需要仔细处理和验证。
05:30
数据处理的复杂性要求研究人员具备一定的技术背景,以便有效地使用各种软件工具。这不仅包括编程技能,还需要理解数据生成和分析的基本原理。
05:52
在分析过程中,选择合适的内核和卷积方法会影响结果的精确度。使用正确的工具和算法可以帮助提高模型的性能和可靠性。
如果觉得英文字幕断断续续的,也可以让大模型帮我们翻译、整理,看视频:
以下视频来源于
软件质量报道
已关注
关注
重播分享赞
关闭
观看更多
更多
退出全屏
视频加载失败,请刷新页面再试
整理成的文字是:
开头的时间删去后,翻译润色的内容如下:
没有机会,根本没有机会,真是的,这根本不可能。我在208行上,你在什么地方?天哪,这代码居然跑了,简直就是我的代码的真实写照。我知道它使用了合成数据和自己的函数,但这实在是太离谱了。居然达到200行,我在下一行写的是什么?天呐, الناس不理解。我不知道人们不理解的是什么。这段对话是从我给出论文的方法部分开始的。嘿,你知道吗,首先要赞美我自己,写了这么出色的方法部分,许多方法部分其实写得很糟糕。如果真的去读一些论文,会发现大多数方法部分都很糟糕,所以我为自己的好方法部分感到骄傲。
不过,天哪,我的天啊。好吧,让我们来稍微比较一下,它用了多少行?200行。我是说,这些可视化其实并不算什么,全都不算,215行。我也有很多图表,我的代码就在这里。现在这首歌的气氛真是太合适了,我感觉这就是现在的心情。音乐呢?悲伤的音乐在哪里?你有千百次机会,等等,它重构了,花了六七次尝试。是的,我没有展示给它我的代码,这才是疯狂的地方。我告诉你,只是让它读我的论文,我们大概给了它一两个提示。我觉得我们给它提示大概有三次,记得是01的提示。
我来数数,可能是……一次,两次,如果大家能记得的话,三次,四次,哦,糟糕,算错了。我记得好像是四次,五次,……六次,我觉得这就是它,我没给它任何示例代码,也没有给它我的GitHub库。我只是告诉它,给了它我论文的描述,我简单复制了论文左边的代码部分,然后说:“嘿,我的代码是这样的,你能帮我写一个函数吗?”不过,我要插句插曲,作为一个实际完成这项工作的人的提醒,确实有一些输入是需要额外处理的,比如它是如何生成输入的,没错,我让它生成输入项,所以它才跑起来。
有些人会说,这只是过度解释。是的,也许这有点像过度解释。但当你看到这些嘈杂的数据和模型时,确实有几个输入需要额外的工作,比如掩模等。你需要打开其他程序来进行一些额外的工作,这些东西可不是免费得来的。用的还是一些分析函数。我能更好地解释的是,你在我论文中看到的这些曲线,实际上是你需要输入到代码中的实际数据,这需要在其他软件中完成。因为另有一款软件会处理这些星系图像,进行拟合与分析,所以依然有很多工作需要完成。
总之,这用的是合成生成的数据,但它确实完成了我希望它执行的操作。我可能需要再次检查,某些小细节,比如边缘效应,或者在卷积时该怎么做。实际上,这正是我在论文中提到的Kernel。所以我原本想说,绝对不可能它会知道这个,但天哪,它居然已经看过我的代码了,甚至可以说它已经遍历了GitHub的所有代码。如果它真的看到了我的代码,那它做得真是太好了。嗯,我觉得现在是个不错的结束时机。
后来为了回答大家一些疑问,这位博士又录制了一个18分钟的视频:
这18分钟时间有点长,我让大模型根据语音整理成摘要文字,咱们能在2分钟就看完了:


这篇文章看完,你也感到,全程我也都借助大模型帮我做事:解读视频、翻译字幕文字、润色字幕文字、对长篇内容生成摘要等等,
我们实实在在进入了大模型时代,它一直在身边帮助我们做事情。








 京公网安备 11011402013531号
京公网安备 11011402013531号