AI比人还会玩。
译/依光流
在今年日本CEDEC开发者大会上,《学园偶像大师》(后简称学马仕)开发商QualiArts,以及QualiArts母公司CyberAgent,共同分享了他们对于AI技术在游戏平衡性优化方向上的应用实例。
在上一篇分享中,我们聊到学马仕的3D技术和细节打磨,如果说3D技术并非适用所有游戏,那么今天要聊的AI技术则更具备普适性。
学马仕的玩法比较独特,它的系统框架是类似《赛马娘》的养成模式,但在具体的每个养成环节中,学马仕又加入了名为训练课程,实为卡牌构筑(DBG)的模式。
DBG玩法的魔性,自《杀戮尖塔》走红以后就为人熟知,学马仕的微创新玩法,自然也让粉丝和玩家为之着迷。当然,从开发的角度来看,作为一款需要长期更新的网游,势必要在基础的DBG过程中不断加入新卡,那么卡牌的平衡性调整就会面临快速增长且长期的压力。
所以学马仕项目组借助深层强化学习开发了两套卡牌游戏AI,以及一套平衡性调整支持系统,来解决游戏加入新卡牌后的平衡问题。

左:CyberAgent 游戏和娱乐部门AI战略总部研究工程师伊原滉也;右:QualiArts那須勇弥。
具体来说「平衡性调整的难点」。
学马仕里玩家需要先构筑卡组,在养成环节的课程玩法中,从牌山里抽取手牌并打出,同时卡牌产生的效果也会随情况而变化。
因此根据卡牌组合情况的不同,即使卡组里存在所谓破坏平衡的卡牌,开发组也很难通过人力准确地找到它。
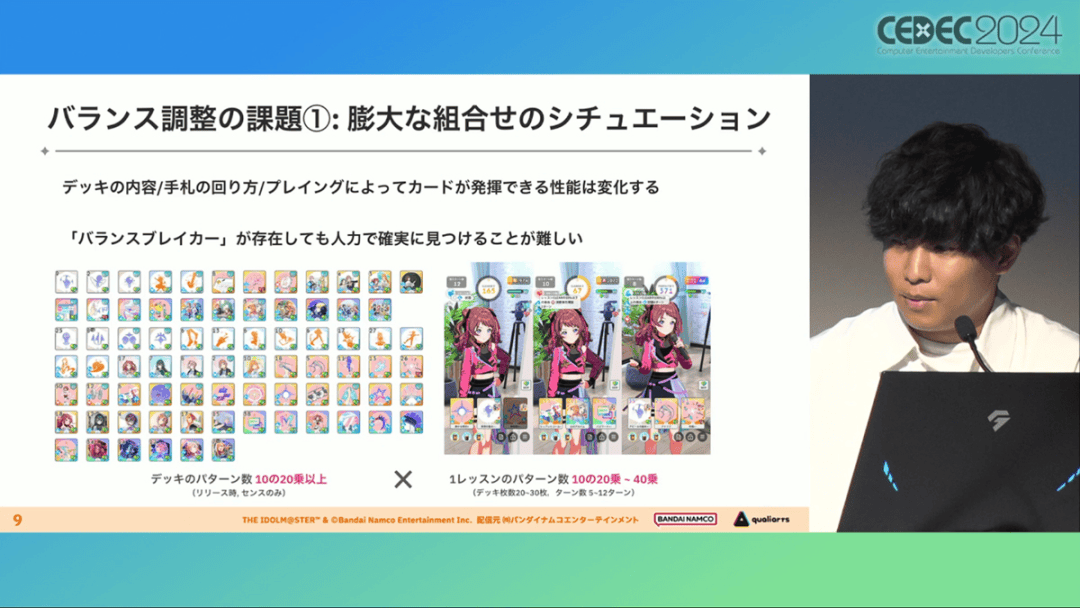
制作组的应对方法,一是用灰盒最佳化技术,生成能够在庞大的组合当中寻找最强卡组的「卡组探索AI」,二是用深层强化学习技术,生成可以尝试各种对局的「课程AI」。两者协同之下,就能解决对应问题。

由于学马仕要考虑到长线运营,所以短期内增加的新卡牌也是一种挑战。毕竟,每个月都要实装新卡的工作流程里面,如果AI的学习时间在10天以上,那么平衡性调整之后连验证时间都留不下来。
所以,制作组对指定学习模型,尝试了一种将追加数据进行转移学习的方法。这种方法的效率远比重复「从头开始学习」的效率更高,把超过10天的学习过程,缩减到10个小时的水准。同时催生了「允许策划方完成模拟的平衡调整支持系统」。
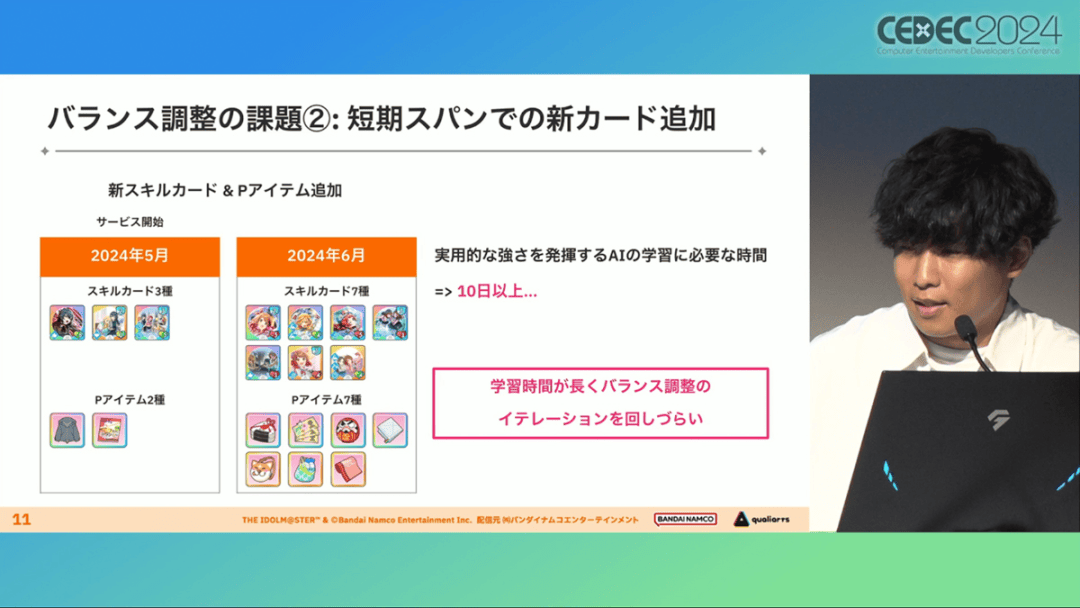
其中,QualiArts负责开发游戏内逻辑,并为平衡调整支持系统构建Web应用程序/基础设施,而CyberAgent负责开发卡组探索AI和课程AI。

01
什么是平衡调整支持系统?
「课程AI」的训练
项目组对于「课程AI」的要求如下:
1.任何情况下都可以打出任何牌;
2.每次游玩的时间小于0.1秒;
3.从添加新卡到确认结果的时间在36小时以下。
换句话说,AI需要以最高效率、最快速度为目标,在更改主数据后36小时内进行学习,并生成易于理解的模拟结果。
学马仕的课程玩法,可以看做马尔可夫决策过程(MDP)来进行建模。这个模型会根据当前的「状态」和「行动」,精确得出下一个「状态」。
将上述模型与蒙特卡罗树方法(MCTS)的博弈树搜索方法相结合,我们可以不断接近更精确的最优行为。顺便一提,其背后的原理与计算机读取将棋或围棋的走法相同。


但上述方法的问题是计算时间较长,执行一个包含9个回合的课程,平均消耗的时间为1416.2秒。
作为解决方案,制作组采用了一种旨在使用「深度强化学习」来近似最佳游戏行为的方案。简而言之,就是让人工智能体验各种情况并通过反复试验来学习。
结果来看,制作组得到的AI,可以打出与 MCTS 相当的分数,并且打一局牌的时间可以控制在0.1秒以内。如下图,虽然平均成绩稍低,但平均单局时长符合0.1秒的要求,相当于相同时间内,可以利用AI进行14000倍以上的对局测试。

此外,在不断添加新卡的运营情况下,制作组必须解决课程AI的学习时间问题。这是因为,要达到上述性能水平,AI需要对局至少3亿次,相当于耗时300小时。
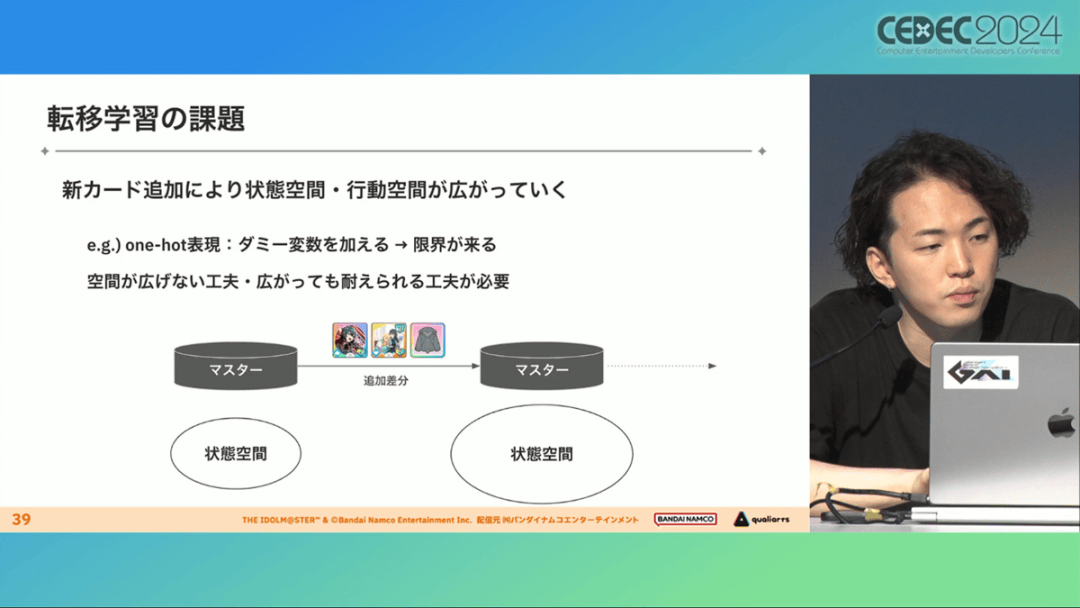
然而,随着新卡数量的不断增加,这种机制将达到上限,因此制作组使用大规模语言模型(LLM,据说使用了 OpenAI 的 Embeddings API)中的文本嵌入来表达状态。
通过使用卡牌效果文本而不是游戏内的结构数据,该系统可以无视产品画面样式的变化,并且具有无需额外学习即可引入新卡牌的优点。

结果来看,前文提到的迁移学习能在更短的时间内完成,相比在相同时间内使用从头学习的模式,也能获得更精确的对局过程。
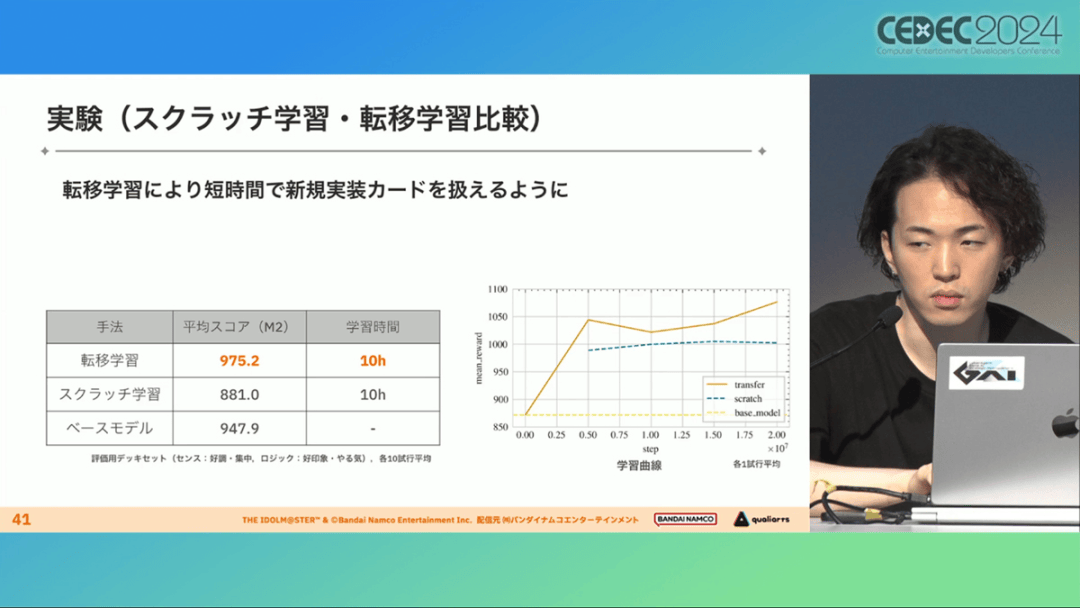
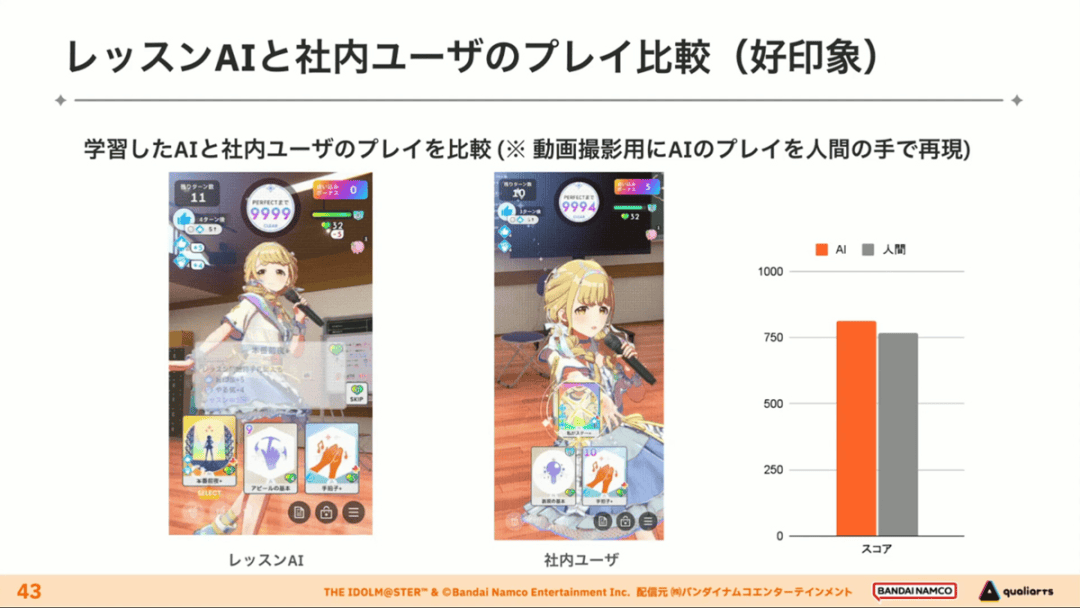
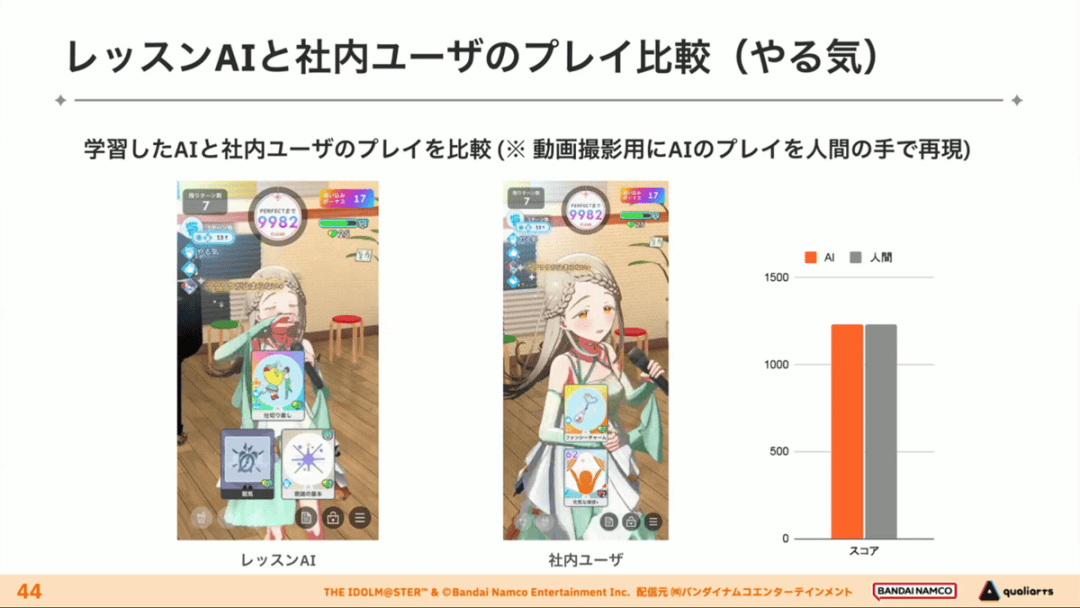
经过上述方式训练出来的课程AI,玩起游戏来已经与不逊色于人类,甚至与人类十分接近了。
即使与制作组内熟悉学马仕的成员相比,课程AI有时在分数上还能胜过这些玩家,而且哪怕打法上的差别虽然只是一招,带来的差距也十分明显。
03
卡组构筑AI对LLM的应用
开发「卡组构筑AI」的目的,是为了发现可以破坏游戏平衡的得分最高的卡组。制作组认为,当AI打出极端高分的时候,往往会关联到太强的卡牌或卡组。
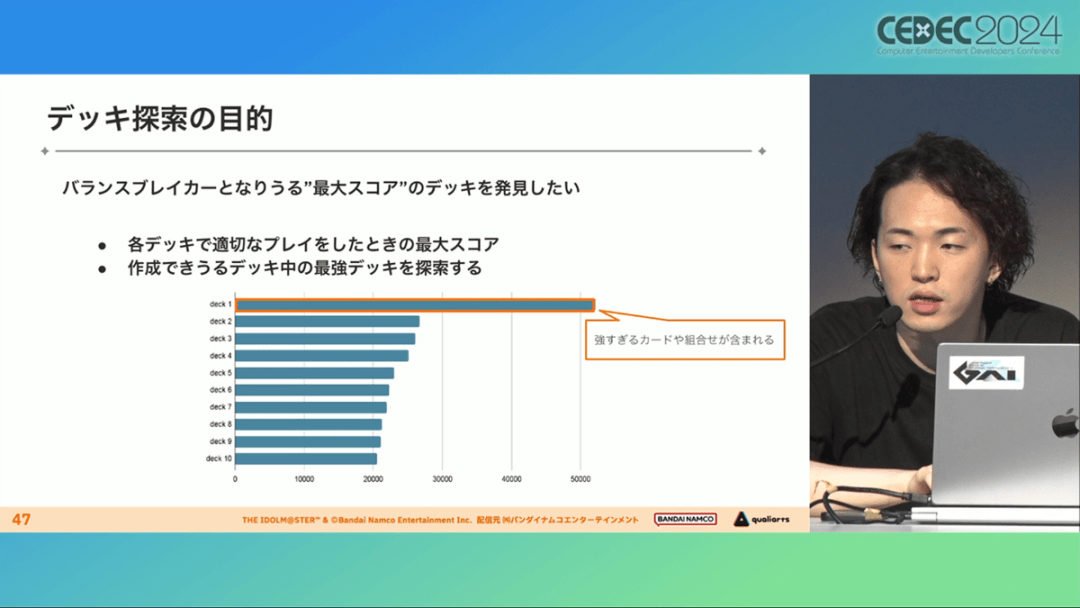
哪怕按照游戏刚上线时的卡牌和道具来算,其组合数也十分庞大(超过10的20次方),并且每次更新时都重新计算和排查一遍的做法也很不切实际。
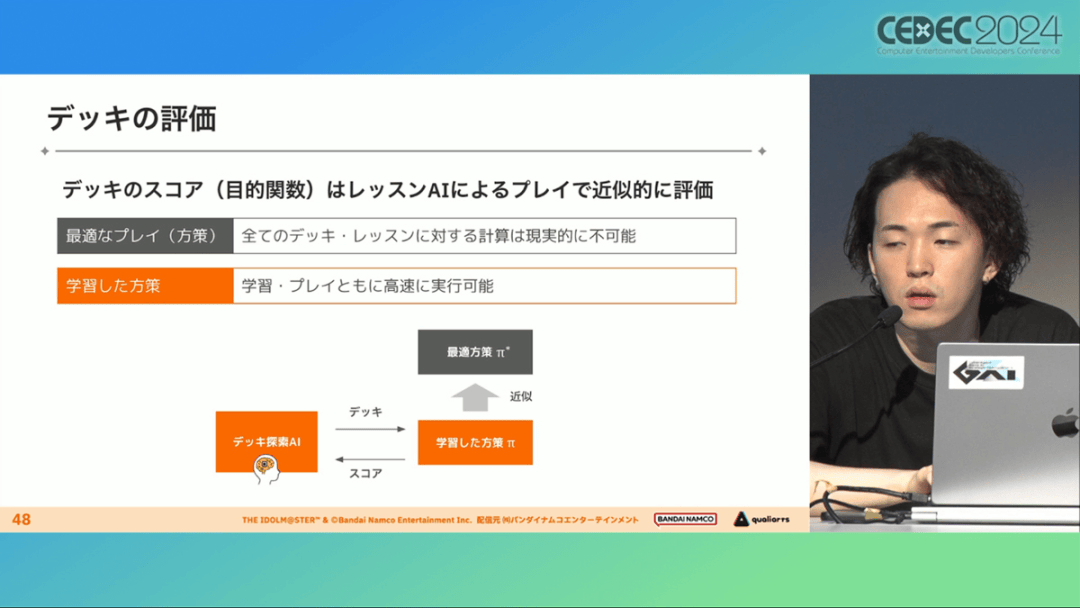
因此,制作组没有使用暴力解决问题的「黑盒优化」技术,而是采用了与问题部分关联的「灰盒优化」技术。此外,这里还采用了使用LLM的文本嵌入技术。


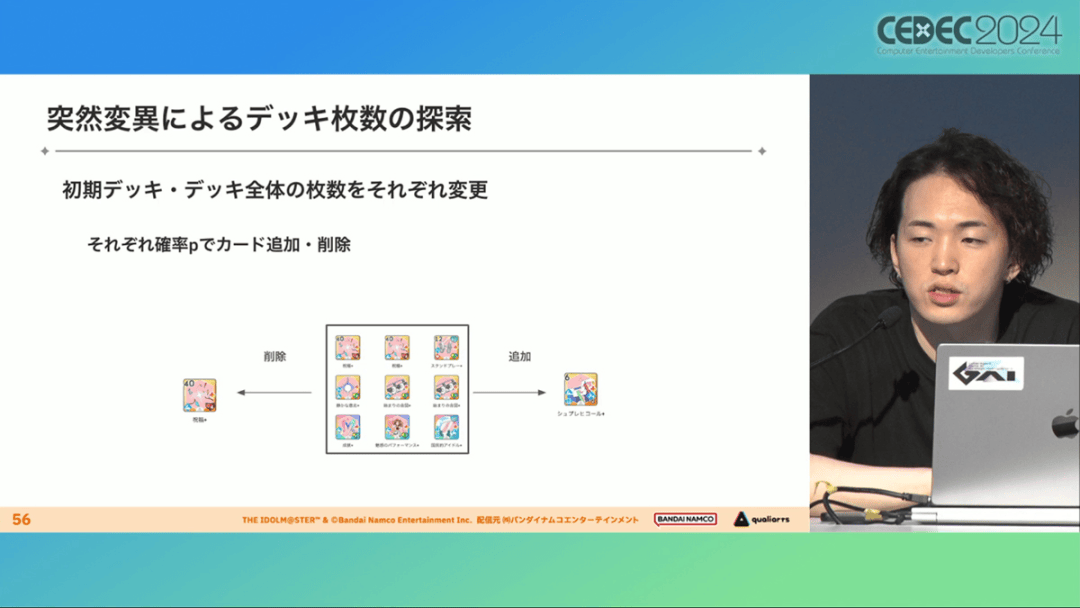
卡组探索算法采用了遗传算法。这个算法机制,会将两个卡组组合起来生成子代卡组,而后评估高分解法,再将优秀解法继续组合生成下一代,并在其中通过引起突发变化来寻找(近似)最佳解。

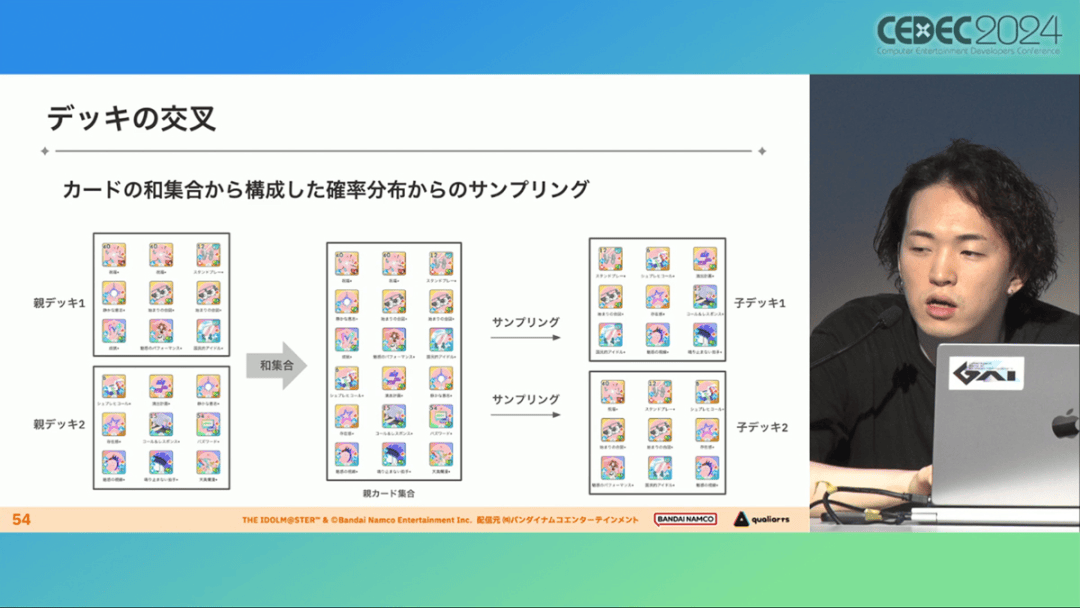
该算法一般用作黑盒优化的框架,但这次通过引入LLM向量化的卡牌信息,实现为灰盒优化算法。
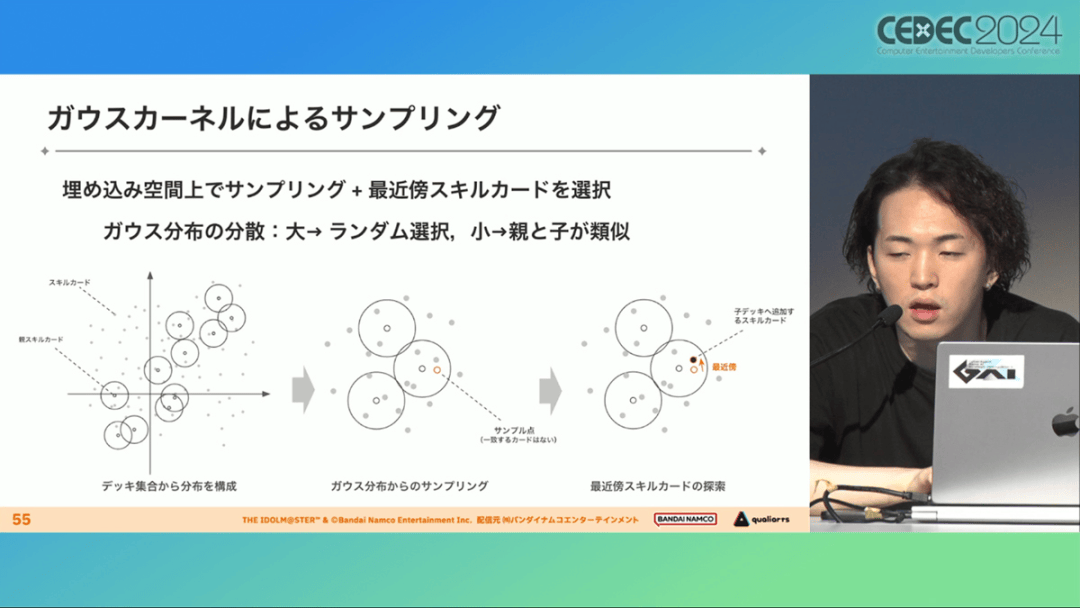
具体来说,是在卡组集合中构建函数分布,并从高斯分布中进行点的采样,再根据有空位的点附近寻找卡牌,而后将卡牌加入卡组。如果方差大,则生成结果接近随机选择,如果方差小,则生成结果是亲代子代卡组相近。
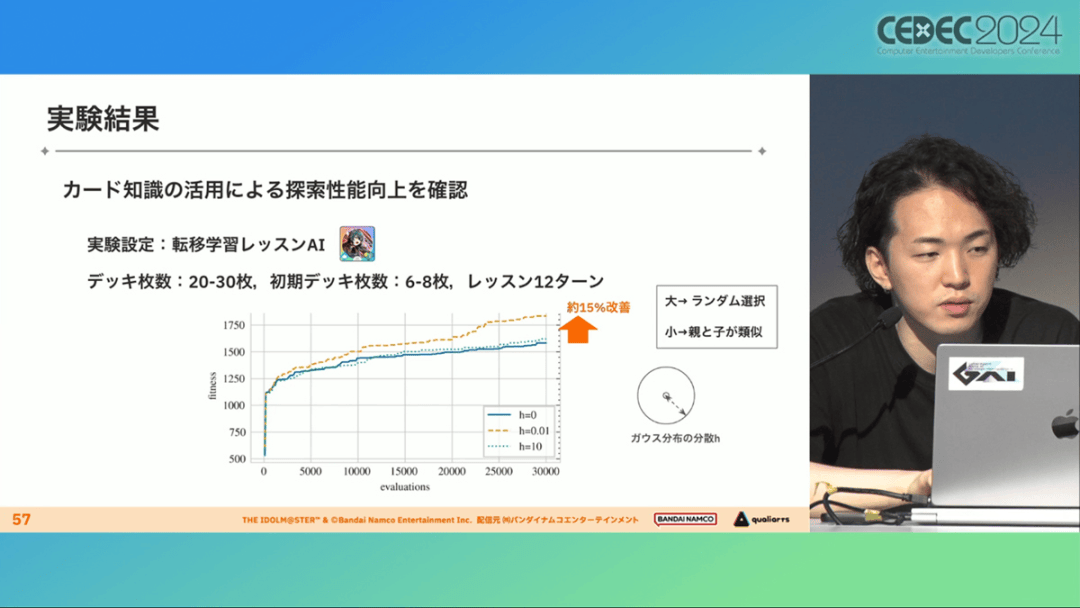
以上尝试的结果如下:
让一个经过迁移学习的AI执行卡组探索时,设定卡组总数为20~30张牌、玩家初始卡组数量为6~8张牌、课程进行12轮,能看到,相比完全随机采样算法,生成的结果效率提高了约15%。
通过使用这些平衡调整支持系统,学马仕自服务开始以来,已经模拟了超过1亿套卡组和10亿次课程。给项目组带来的好处,是调整和优化了很多人力无法顾及的卡组和流派。

如今,绝大多数游戏对AI的应用还是停留在AIGC生成资源的方面,而我们从学马仕的案例来看,AI对于游戏优化测试、平衡性调整,也有不小的帮助。
且不论此前业内「AI将淘汰99%从业者」的论断,至少当下来看,掌握更多的AI技术,确实也能帮我们提高研发效率,优化游戏素质。
文章
https://www.4gamer.net/games/778/G077853/20240822052/
编译整理
招聘内容编辑,
|
| |
||
(星标可第一时间收到推送和完整封面)







 京公网安备 11011402013531号
京公网安备 11011402013531号